
As we shared in a previous blog post a few weeks back, we recently moved Trulia’s property recommender workflow to AWS. We’ve also recently developed new services and deployed them on AWS, which was a brand new process for us, since we had traditionally been deploying similar services in our data center. In this post, we’ll discuss the new process we developed to deploy to AWS, along with lessons learned.
For many of these micro services, we leverage Terraform to handle the continuous integration of code into our dev/stage/production environments.
Developing the Process
To start, we needed to figure out how to deploy an array of micro services to AWS, across multiple teams. We needed the deployment process to be simple and repeatable. Also, it was important to include peer reviewed infrastructure changes into the process. It is important to note that the micro services needing to be deployed were mostly stateless.
The Stack
The technology stack that we put together to tackle this challenge was a combination of Packer/Puppet/Jenkins/Terraform. Packer and Puppet paired up well for us. We have extensive experience with Puppet as a configuration management tool, and coupling it with Packer gave us the ability to save AWS AMIs for deployment into our different environments, while leveraging existing Puppet modules in a masterless setting.

With this technology stack we are able to deliver new AWS AMIs which contain our latest code releases into a targeted environment. The process starts with Jenkins managing the code tests and compilation. We then promote the Jenkins build to a Packer promotion step when we build an AMI that contains the latest code release. Once the AMI is built, we follow up with a final Jenkins promotion step that leverages Terraform’s create_before_destroy lifecycle option to rollout the new AWS Launch Configuration and Auto Scaling Group that contains the new AMI before removing the existing. This method of integration requires that we have intelligent service health checks that ensure the service is in fact healthy. For example, if the service needs to talk to an AWS RDS instance, we bake a RDS connectivity check into the health check. Once the new Auto Scaling group is online and the ELB sees passing health checks from instances in this new group, Terraform then removes the previous Auto Scaling group that contains the prior code release. Here is a visual of this process presented in a infrastructure timeline:
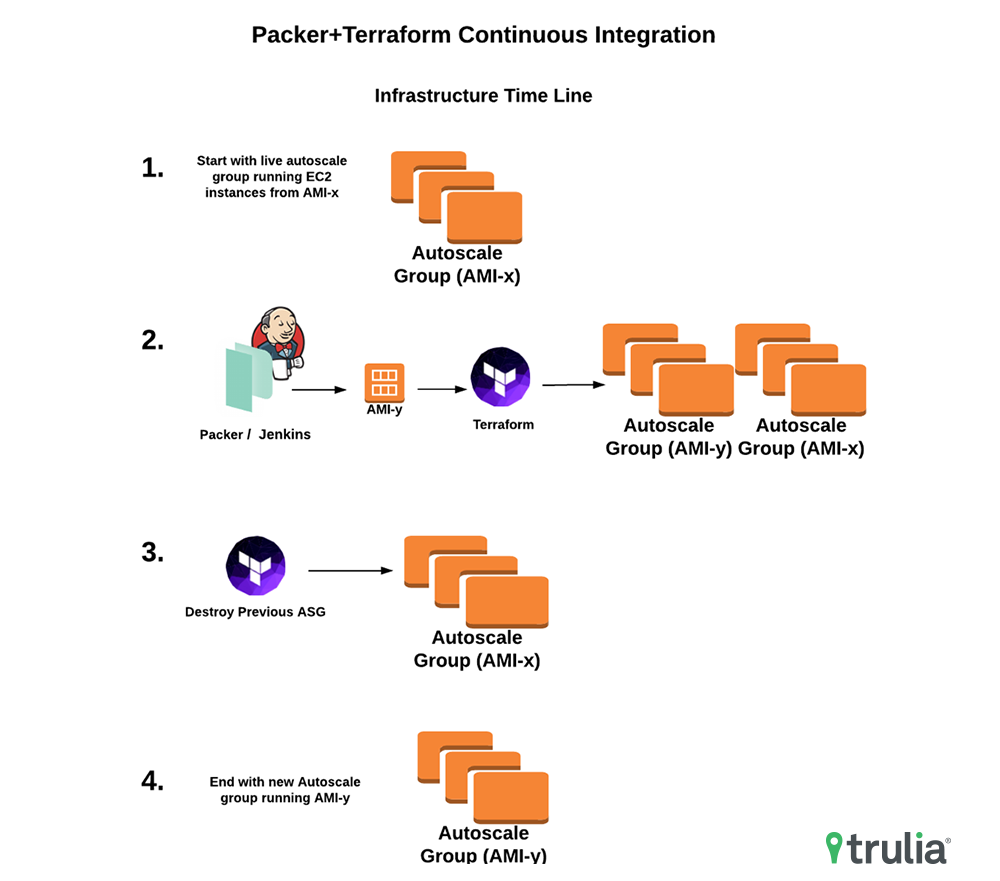
Lessons Learned
This form of continuous integration works well for us when dealing with stateless micro services. However, it is not perfect. We have dozens of micro services to deploy using almost exactly the same Terraform. Each team’s set of micro services have built into their code base a ‘deployment’ folder, which lives alongside their source code. Underneath the deployment folder is the Packer, Puppet and Terraform needed to deploy the service on AWS. To manage the issue of Terraform code drift and copy and paste issues, we turn to using Terraform Modules stored and accessed from Git. This provides the ideal way to share Terraform between teams and micro services, and gives us the ability to upgrade the module. This also allows us to maintain backwards compatibility through the usage of Git tags for reference points. Here is an example of how a reference point is used (see line 2):
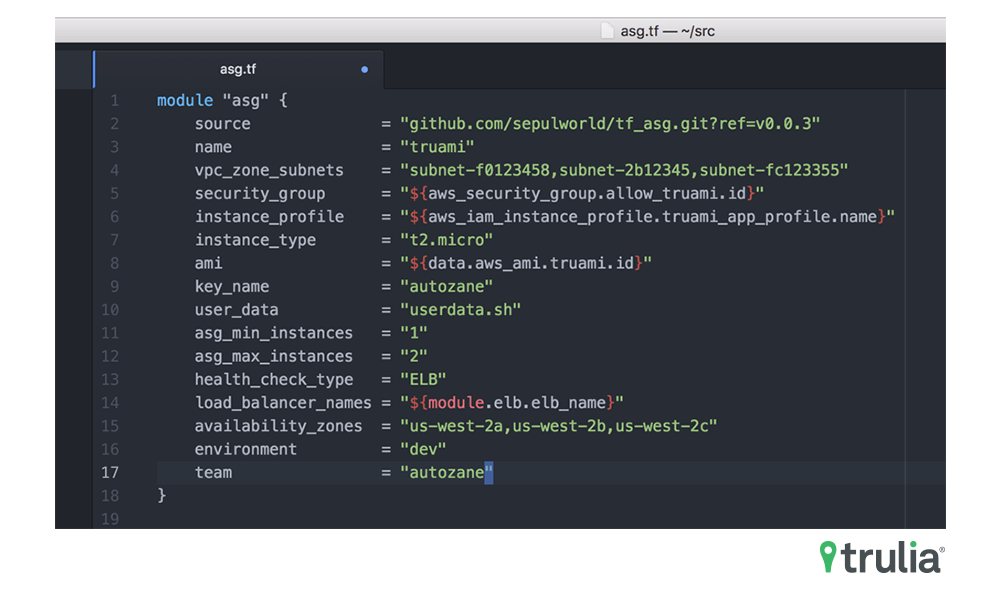
We gave a presentation on this recently at the San Francisco Infrastructure as Code Meetup. If you’d like a more detailed look at our usage of Terraform Modules sourced from Git, please see the modules section of our meetup presentation. The actual slides for this presentation can be found here. Git links for reference:
Example micro service (Golang application to display AMI version and other details of EC2 instances): https://github.com/sepulworld/terraform-examples/tree/master/meetup_san_francisco_infrastructure_as_code
Terraform Modules used by this micro service:
https://github.com/sepulworld/tf_asg – Terraform AWS Auto Scaling Group module
https://github.com/sepulworld/tf_elb – Terraform AWS ELB module
This setup isn’t a ‘silver bullet’ for all deployments on AWS. You still need to design your application to run on AWS where EC2 instances may go offline at any moment. It probably wouldn’t work for moving a monolithic data center focused application into the cloud. For a stateless service with well designed health checks this Packer+Terraform continuous integration solution is straightforward and easy to implement for teams.
Stay tuned here for more about our use of AWS.

