The Trulia Data Engineering team loves Big Data. We’re currently focused on our user personalization project, where we digest an ever-increasing body of user interactions to create instant, on-the-fly customizable views of our pages so users always see the most relevant content. Meaning, if you’re interested in Victorian homes for sale, we’ll ensure you see Victorian style homes first in your search results.
On a daily basis, we process more than 1.5 Terabytes of data at Trulia, and that number is projected to at least double in the months ahead. In this post, I’ll explain how we’re able to crunch all this data, and capture and understand each user’s intent to ensure relevancy.
Where We Began
We started our personalization project a year ago by writing Hadoop jobs using the pure Java Map/Reduce API. At the time, we only had a few jobs doing fairly simple things. Our code was small and manageable, and everything was working fine. However, as we started adding more functionality and jobs to our pipeline, and more sophisticated logic in our code, we started hitting the limits of the Java API. We found ourselves either writing the same boiler plate code for every job, or, when we wanted to do more advanced things like joining two data sets or adding complex Data Science logic, having to write extremely complicated and bug prone code that was hard to debug when run against our vast dataset.
It became clear we needed a higher-level framework that would allow us to focus more on our logic and less on the Map/Reduce plumping side. We looked at various solutions, including PIG and Cascading, but in the end, Scalding is the framework that wooed us.
Where We Are Now
Scalding, a framework developed at Twitter and open sourced in 2013, is essentially Cascading using Scala. While we loved Cascading’s simple API, including the plethora of taps and sinks that come out of the box, and its pipes that simplify very complex tasks like a Map/Reduce join or group-by, Scalding gives us the best of both words – all the Cascading goodies, plus the chance to work with a Functional Programming language like Scala.
Why Scala? Working with Big Data implies a write-once/read-many paradigm and Scala’s immutable data structures and general bias towards writing side-effect free code was a natural fit for us. Writing code that focuses on immutability allows us to reason better about the correctness of our algorithms, and not worry about unpredictable timing or concurrency issues and bugs. Since using it, we’ve written less boiler plate code than when using Java, and we’re able to take advantage of Scala’s abstractions to deal with nulls (using Option[]’s) and exceptions (using Try[]’s). We’re also using pattern matching extensively and the use of implicits allows us to cleanly group multiple operations in one function that can be applied to a plain old Cascading Pipe, creating a beautifully crafted fluent style of code.
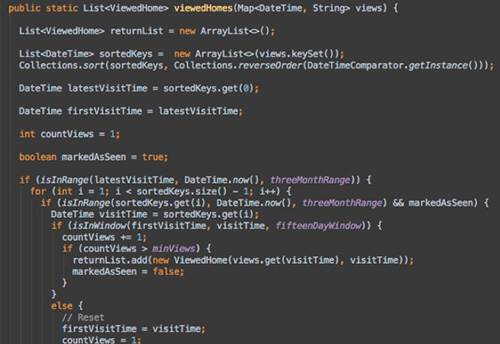
For example, say we wanted to identify houses that users look at a lot but don’t save to their favorites. Let’s classify these as any houses visited more than four times in a two-week window in the last three months. A fairly decent Java implementation using all properties the user has seen during her lifetime as input data would look like this:
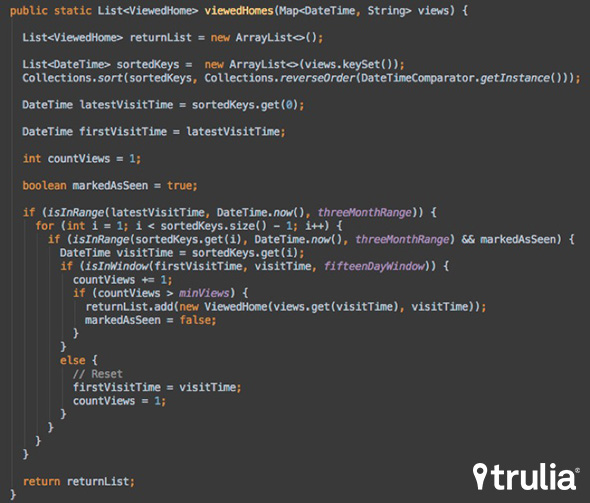
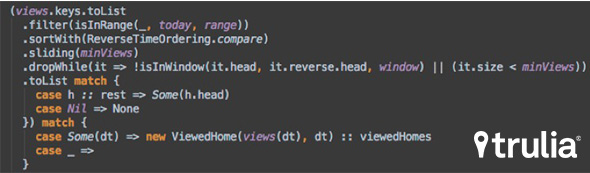
The same implementation in Scala looks like this, intuitive and clean:
The Benefits
Using Scalding and Scala, we’ve managed to reduce our code base from approximately 2,000 lines of Java code to about 300 lines of Scala code. We’re also able to test our pipelines end-to-end using JobTest and increase our code coverage. Scalding and Scala shorten our development times and allow us to really focus on serving only relevant content to our users. We’re now fully committed to using Scala for more parts of our code, and we’re extending its usage to more groups in our organization.

