Our goal at Trulia is to make the home search easier, and we leverage data science to help us achieve that. We’ve shared pieces of how we’re using computer vision to surface better images at the right time, and we’ve shared a bit about how Trulia engages consumers through its home recommendation system. Today, we’ll talk about how and why Trulia builds machine learned (ML) consumer engagement prediction models.
First, an overview. In Trulia’s case, messages are frequently sent to notify consumers of real estate updates (new listings, changes in properties they have expressed interest in, etc.), to help them quickly and efficiently find their next home. If used carefully, these messages can be very valuable in keeping consumers engaged with Trulia. So, we focused first on building engagement prediction models for emails to ensure we send only messages that are of interest to consumers.
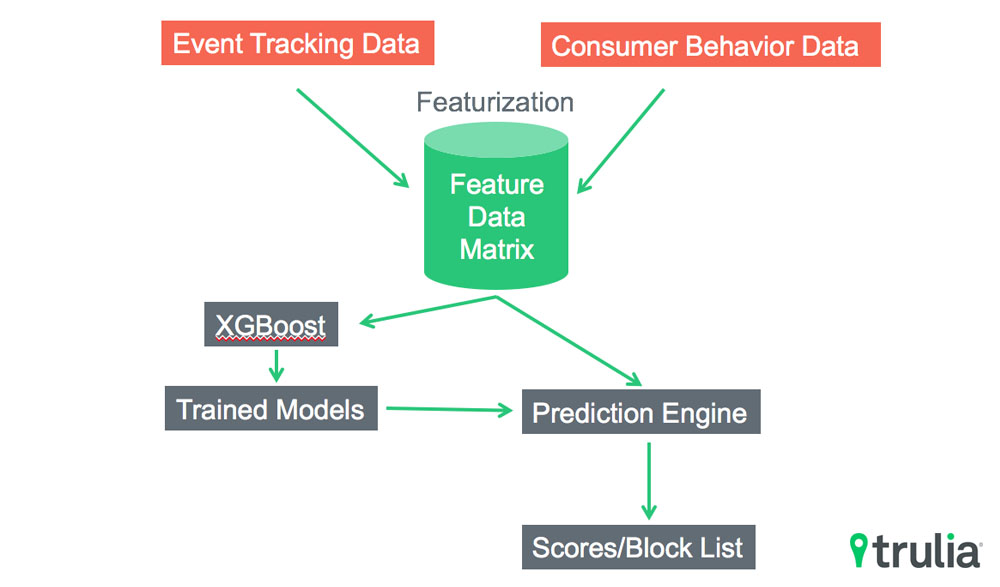
The framework was developed in Apache Spark (Fig. 1). In short, it allows Trulia to determine the probability that someone will engage with a given email campaign. If the probability is low, we won’t send or display. Here’s how the framework is built:
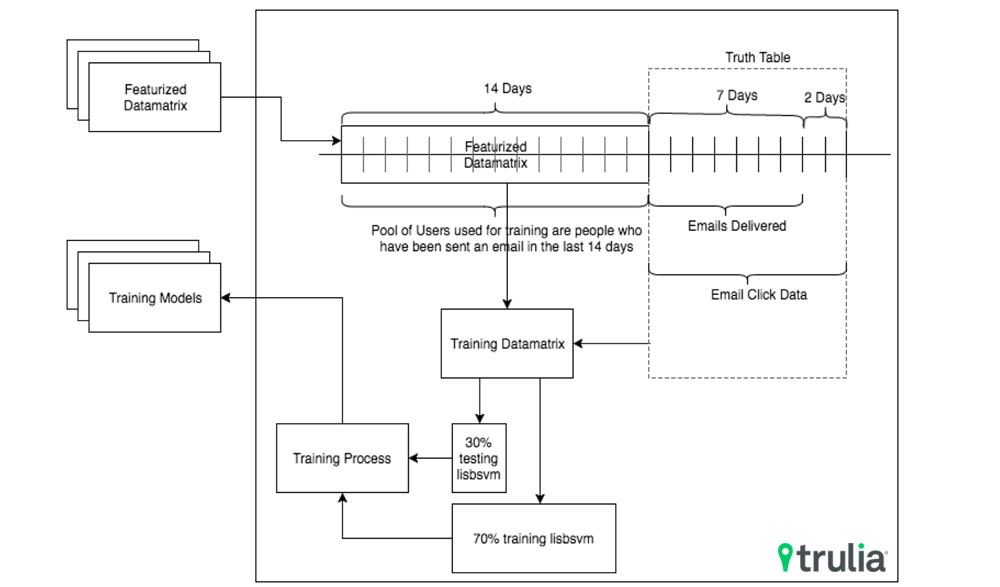
From our email event tracking logs, we have data on whether consumers are engaging with the various emails that are sent daily across our different email campaign types (e.g. Rental Saved Search Alert email campaign or Recommended For Sale Homes email campaign). We cast a binary classification problem for each email campaign type: the truth label to predict for each consumer is 0 or 1 (i.e. the consumer has-not-clicked or clicked on an email campaign in a seven-day period with an additional 2-day period to collect click data). We then construct a training data matrix, where each row represents a consumer, with the truth label column specified above, and the rest of the columns consist of the various features obtained prior to the seven-day period. The features we use fall roughly into these categories: consumer based features, consumer activity on Trulia and email activity based features. This large-scale data processing and feature engineering is done in PySpark on AWS. Please see Fig. 2 for illustration.
With the training data matrix built, we train ML models with Gradient Boosting Machine algorithm by leveraging the open source XGBoost package. We then deploy the ML model to predict daily on each consumer and put consumers with a very low probability of click on a temporary do-not-send list. Our online AB test results have shown that with this approach, click through rates can improve in the mid-double digit range while sacrificing no click through traffic loss. One important learning is that a random fraction of users on the do-not-send list needs to be removed from the list and become email recipients, since we need to re-train our model for the entire population of consumers based on their sends and clicks on a continuous basis. Blocking sends outright will significantly reduce the population of consumers to continuously re-train the ML model.
In summary, the technology stack we used include:
- PySpark for tracking data processing and feature engineering
- Parquet for flexible columnar data storage
- Jupyter IPython notebook for rapid code development, experimentation and visualization
- Python/XGBoost for ML model training and prediction
- The entire framework runs on Amazon Web Services (AWS)
Beyond just predicting email clicks, we have expanded this ML framework to predict other types of consumer engagements, such as contacting a real estate agent or mortgage broker and clicking on mobile app pushes.
There are many exciting future projects in further expanding the ML framework for engagement prediction. One potential project is to explore predicting consumers’ near-term engagement trajectory; for consumers predicted to become less and less engaged over time, we can perhaps target them with re-activation content. Another potential project is to transform the current batch based framework to support real-time featurization and prediction. No matter which project we work on next, since implementing our prediction models, we have seen significant increases in user engagement on Trulia and we look forward to what’s ahead. Stay tuned for more.

