When house hunting, seeing relevant content makes the process easy and enjoyable. Houses are just as different as people, which is why finding the best house on the block is irrelevant. The real goal is finding the home that’s best for you. This is what we call personal relevancy.
Specifically, at Trulia, the relevancy challenge we’re faced with is personally matching hundreds of millions of consumers with hundreds of millions of houses. The process requires massive computing resources and complex data analysis that Trulia, and likely other companies in our industry, couldn’t necessarily afford ten years ago.
But now, we can. This is a result of a number of factors, including commodity hardware becoming cheaper as technology improves (following Moore’s Law), and the prevalence of distributed computing software to harness these machines for big data, thanks to open source community contributions such as Apache Hadoop. And, perhaps most importantly, it’s because at Trulia we now have the manpower and resources to leverage this available hardware and software.
As a first step on this journey to personal relevancy, we formed a dedicated personalization team. The team’s first project was to build a personalization hub that collects and processes users’ activity events to create their digital signatures. In this post, I’m going to introduce the high-level architecture of the hub.
The Technical Architecture
We broke the architecture into three pieces: 1) real-time event tracking infrastructure, 2) transformation infrastructure from events to user traits, 3) user trait serving infrastructure.
Event Tracking Infrastructure
Typically, a consumer visits Trulia, searches for homes with a certain criteria, reviews the search results, and clicks through to the homes that caught her eye; she flips through photos and reviews certain information. Through these activities, she tells us a lot about what she’s looking for. Having a reliable event tracking infrastructure in place is very important because everything starts from this data.
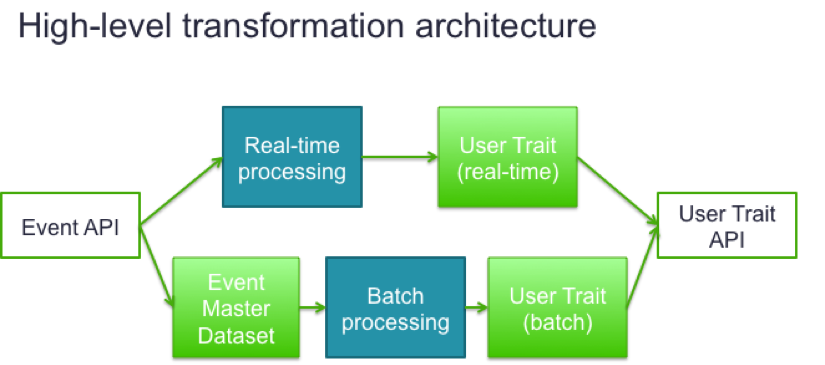
It’s common wisdom in the consumer analytics community that consumer data is not always enough when it comes down to an individual level. For that reason, we developed an Event API. It’s a RESTful web service to keep the tracking in real-time. Also, it validates the reported events against the schema so we have a reliable dataset standardized across all Trulia platforms. Once the event passes the validation, the Event API guarantees its delivery to the Event Master Dataset via multiple levels of fault-tolerant mechanisms.
The Event Master Dataset is a data repository that keeps various kinds of user actions on Trulia (e.g. searches, saved homes and search filters, agent contact, etc.). Currently, we capture billions of events per month, and expect this to grow in 2016.
Transformation infrastructure from events to user traits
Taking the Event Master Dataset as input, we then build the User Trait Dataset. It’s another data repository that bundles each user’s activity summary (e.g. per-home engagement intensity), specific milestones (e.g. last visited time), and preference (e.g. location and price range). This user trait captures the user’s holistic view by merging activities across platforms. We also build the user trait of unregistered users as well to personalize their single-platform experience.
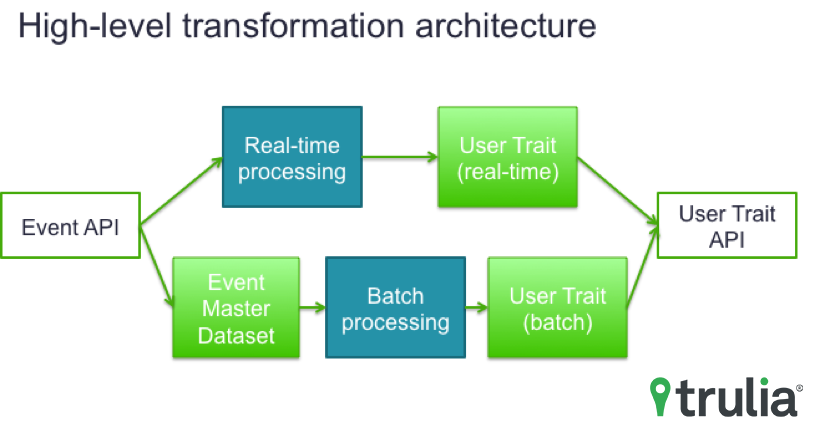
Processing the billions of events we collect into hundreds of millions of user traits is a non-trivial, but massive, undertaking. While batch processing gives us flexibility in algorithm and efficiency in processing, stream processing allows us to keep the computed user trait up-to-date in real-time. Thus, we employed Lambda Architecture to combine the merits of both sides. This transformation allows us to view each user’s sequence of activities in time order, and run data science models and business rules to capture various personalized consumer insights.
User Trait Serving Infrastructure
The User Trait Dataset serves many downstream products in two integration patterns. One group of products personalizes the experience when consumers visit Trulia. To serve this random-access short-latency access, we load the user trait data in NoSQL DB and serve it via a User Trait API, a RESTful web service.
The other group of products prefers a snapshot of the dataset in a filtered view to load in bulk, such as through consumer analytics and reporting, or targeted audience marketing. To serve this bulk transfer pattern, we export the data as part of the batch transformation flow.
Next Steps
It’s an accomplishment to build such a large platform from scratch in just one year, and to be able to already demonstrate the initial value of it. But, we’re not done yet, so stay tuned for more, and feel free to share any questions or comments you have below.

