
Earlier this year, we published an article about technical debt in which Tim Correia, SVP and General Manager of Trulia, shared his perspective of what it is, where it comes from, and how you can manage it. As we inch closer to Trulia’s 13th anniversary, we have grown to serve tens of millions of homebuyers and renters each month, helping them discover homes and neighborhoods they’ll love, and requiring our systems to fulfill thousands of requests, such as home search results, per second. To do this, our platform must leverage the latest technologies to enhance performance and functionality. However, the technical debt that we’ve accumulated over the years as a byproduct of our success and rapid growth has made this challenging.
At the end of 2017, Trulia engineering gathered representatives from across the organization (plus some outside observers) for a two day “on-site” to evaluate the state of our system, and the needs of the developers and the business. The group connected obstacles in getting updates delivered to the level of technical debt accumulated over the years, and since leaders of the business were familiar with the costs of carrying technical debt, the business aligned with the engineering organization’s initiative to focus on retiring much of the debt. In addition to retiring the debt, we identified needs for improved integration and deployment processes: teams had varying capabilities to verify proper integration prior to production and delivering code to production that often required a great deal of cross-team coordination.
After reviewing the needs identified, clear priorities emerged:
- Break up the system into microservices
- Institute continuous delivery to production
- Assure developers hold responsibility for the quality of their products
Trulia has built a number of back-end processing microservices over the last few years, resulting in some productivity improvements. One of the experiences in the initial implementation of microservices was that different teams emphasized different aspects of the microservices and didn’t have an effective way to learn from one another’s’ experiences or build upon their successes. In order to fill this gap and promulgate best practices and tools across the organization, the role of architect was created for the first time. Additionally, to help teams engage with performance as a practice, we created the role of performance engineer.
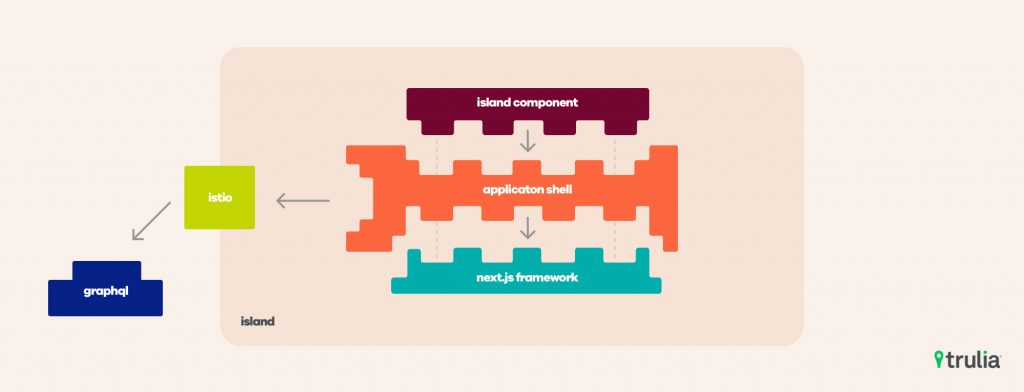
While we’d made some progress in deploying back-end microservices, we didn’t have a solution for dividing the main user experiences of the site into separately-shippable packages. The members of the “on-site” group prioritized work on a solution to enable independently-shippable user experience packages and named these packages “islands.” Separately deployed “islands” of user experience would allow each team to own its destiny all the way to production.
The “islands” are autonomous and independent components, with a flexible technology stack and freedom to innovate within the bounds of an “application shell” that provides common services that all of our UI “islands” are expected to use (the subject of an upcoming article). This allows developers to focus on creating compelling experiences for our users and rapidly deliver the new capabilities needed by the business. Among the key technologies that enable this new platform are NextJS from ZEIT, Istio, and GraphQL, which we’ll discuss in future posts.
To assure that teams are able to deliver independently from one another, and that there is one ‘source of truth’ in the system, we have gathered representatives from across the Trulia engineering organization into two parallel workgroups: Engineering Principles and Microservices Strategy. These workgroups are tasked with producing guidance to engineers in two dimensions: how to weigh trade-offs when making technical decisions, and what the technical architecture we’re striving for should look like.
We are investing in Trulia Engineering Principles with the goal of empowering developers to make decisions in a framework that supports making independent decisions that comport well with one another. We are looking forward to publishing this work in the near future and to reporting on the benefits of a shared vocabulary and its impact on our culture of quality down the road.
From our early experience in building microservices, we’ve learned that teams will benefit from a high-level model that shows where each microservice fits and from standards that allow the teams to consume each others’ services in predictable ways. We are developing our microservices strategy to enable our developers to engage with the model and to build and leverage a common platform.
To enable the “islands” and microservices to ship and scale smoothly (and meet our continuous delivery goals), we’ve developed Jenkins build and deployment pipelines that culminate with deployment into our Kubernetes cluster.
In the coming weeks, we will post details about the structure of our “islands,” our service architecture, and our deployment pipeline.

