At Trulia, it’s our job to make finding a home easy and enjoyable for consumers, and as part of that, we’re always working to ensure they’re seeing the most relevant homes for them. In living out that promise, we developed a machine-learning Property Recommender model that ensures we’re delivering relevant listings, while expanding our target consumer base and improving visit rates, but it took some time to get here.
Once we built the model for our Property Recommender, our goal was to make predictions using the model. The challenge was to come up with a reasonable candidate set to predict on. For example, on average, there are around three million active properties in the market nationwide at a given time, and we might have even more users interested in property recommendations. A brute force method would mean running trillions of user-property pairs against our model, but that is a non-starter. So, we used various heuristics to reduce our candidate set to a more manageable billions number. Anything less would mean not meeting our product requirements on number of users we can recommend properties for.
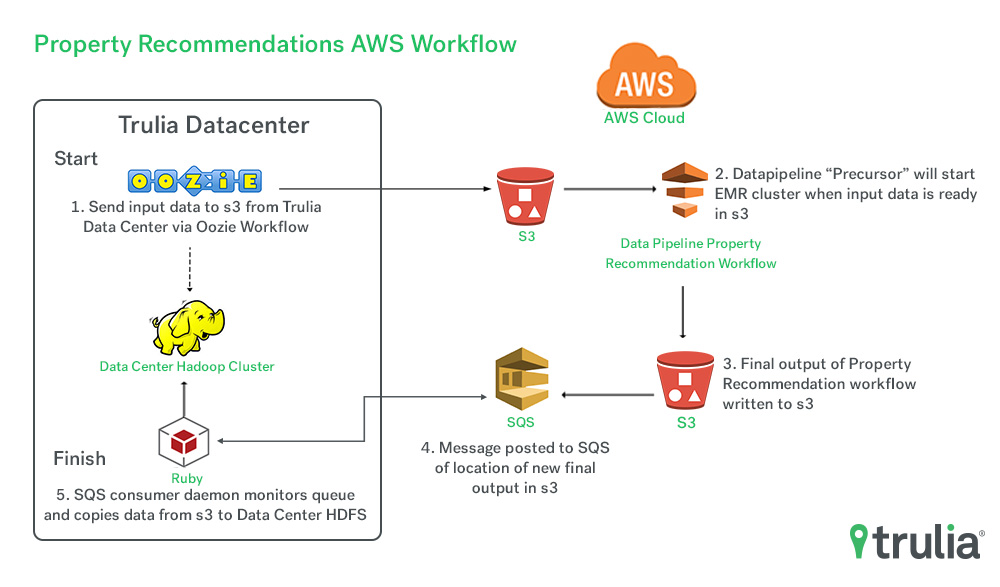
Once that was complete, our Property Recommender workflow was ready for testing. However, we lacked the ability to quickly scale our data center’s Hadoop cluster to meet the resource requirements needed for this workflow. We needed a solution that enabled us to turn on data processing resources on-demand without worrying about shared cluster capacity restraints. For this, we turned to Amazon Web Services (AWS) and their Elastic Map Reduce (EMR) solution. Not only did this give us the flexibility to turn up EMR clusters on-demand, but it also allowed us to save the final output of this workflow in AWS for other Trulia services to leverage. Here’s a look at how we did it:
Migrating from Oozie to AWS Data Pipeline
The Property Recommender workflow was initially configured to run with Oozie. We looked into porting our Oozie configuration over to EMR, but the Oozie application was in a “Sandbox” state on EMR at that time, and we prefered not to use a sandbox application for production. After some additional research, we ended up converting the intermediate steps over to AWS Data Pipeline “HadoopActivity” objects. With Data Pipeline we are able to reliably control all intermediate data processing steps.
Getting the Property Recommender Hadoop workflow running on AWS wasn’t without lessons learned though. First off, we had to climb the decently steep learning curve of using AWS Data Pipeline to manage a workflow, which required a couple of dozen intermediate data processing steps. Configuring the workflow and being able to quickly test changes became a challenge time-wise, since spinning up a new workflow to test a change consumed developer time. To speed up the development of pipeline changes, we implemented some intermediate output directory checks, which allowed us to skip over data processing steps that had already been processed for that day’s run. This sped up the testing quite a bit as it allowed us to not have to rebuild the entire intermediate data sets when we wanted to test a small change in one step in the process.
The handshake between Trulia data center workflows and AWS workflows
Another challenge we faced was how to get our required input data into s3 for processing and how to get the final output back to our data center. For the input data, we are leveraging an Oozie workflow in our data center that copies required input data to s3 via Distcp. Our AWS Data Pipeline job is setup to run on a schedule and when the pipeline starts, it begins with a “Precondition” (that will wait for our required input data to be available for that day in s3). Once the data arrives, the EMR cluster comes up and our Hadoop activities run. To solve the challenge of getting the final output of our pipeline back to the data center, we post a message as a last step of our pipeline to an AWS SQS queue. The message contains the file system URI for the s3 final output and the destination directory we want the data to be placed in in our data center Hadoop cluster. Within our data center, we have a small Ruby daemon that monitors the SQS queue. When a message hits the queue, this consumer application runs a Distcp to copy the data from s3 to our data center.
Optimizing and reducing costs with AWS
Our first attempt at running our jobs in EMR failed miserably. While our data center cluster was schedule challenged, it was certainly not capacity challenged. We were spoiled a bit when it came to having a really beefy cluster at our disposal.
In AWS, we started out with a few hundred m3.2xlarge nodes. We had sporadic success running our workflow in this cluster. After analyzing the Hadoop logs and system performance, we found that the CPU utilization was close to 100 percent with some of our jobs. Our reducers were running out of memory and JVM GC was pegging the CPU. We decided to experiment with r3 instance class. R3’s are memory optimized, providing us lower cost per GB and enhanced networking. With r3.4xlarge instances, and some application level optimization, we got to our first successful run! Additionally, since going through several rounds of optimization, we brought the cost down to a more acceptable cost-per-run.
By choosing to move our Property Recommender workflow onto AWS EMR, we were able to speed up final development and release to production, without having to expand our data center Hadoop cluster. Also, a dedicated EMR solution has given us the ability to test newer versions of cluster software and make configuration changes without having to worry about it impacting other production workflows. We could easily see what this workflow alone required resources and could dial in performance, without affecting other workflows as may be the case in a shared Hadoop environment. This workflow enabled us to deliver more relevant recommendations to a larger set of consumers while increasing visits by double digits.

