There are some instances where a listing’s address can’t be disclosed on a site like Trulia. We honor that, but we still want our consumers to see all active listings, so we have a workaround. Instead of showing the exact location of what we call a “non-disclosure” listing on our maps, we show the listing’s nearest street intersection.
Typically, we geocode all addresses. Geocoding is the process of converting an address to latitude and longitude, which enables the address to be shown on a map. However, non-disclosure properties should not be accurately geocoded, since accurate geocodes can be reverse engineered to addresses. Instead, we compute the nearest street intersection point to the property and display that to the end user. Here’s a look at how Trulia computes the nearest intersection to a given point.
We use TIGER (Topologically Integrated Geographic Encoding and Referencing) streetline data to compute the nearest intersection to a given point. TIGER provides streetline datasets, which include address range, address range features, topological faces, places, and county and state datasets.
Address ranges indicate the starting and ending primary number for a given street line segment, which you can see in the figure below.
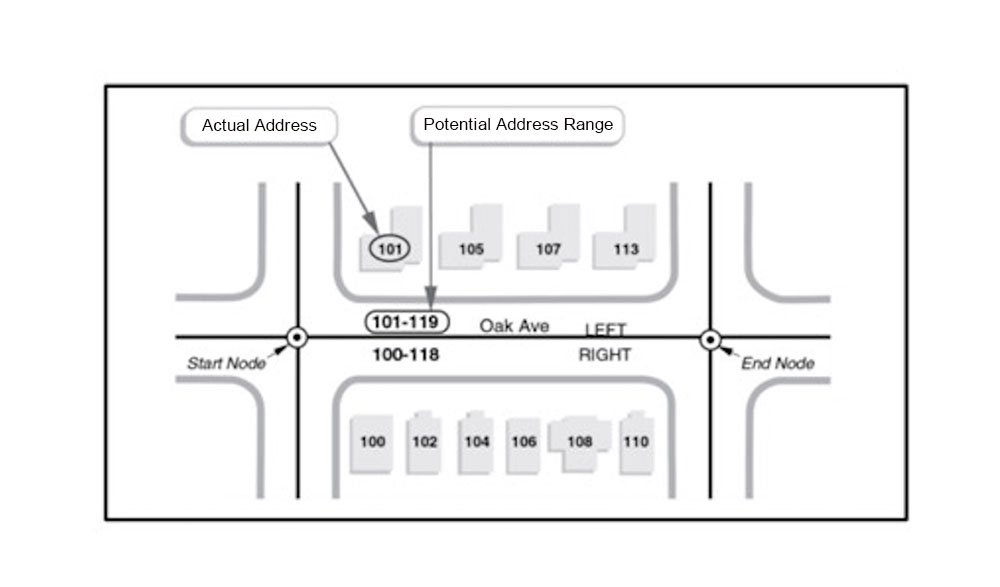
To compute the intersection, we first compute a set of intersecting counties (counties whose boundaries touch) for a given source county. We need to consider intersecting counties because the nearest intersection might fall into a neighboring county, city or zip code. For every source address range in the source county, we find the possible target intersecting ranges. A target intersecting range is identified as the line that intersects with the source range. For example, in the screenshot below, there are four edge records for intersections between First street and Mission street in San Francisco. Each record of source address range to target address range is called EdgeRecordSet. These EdgeRecordSets are stored in avro files (avro is a compact binary data format that is extensively used in big data systems).
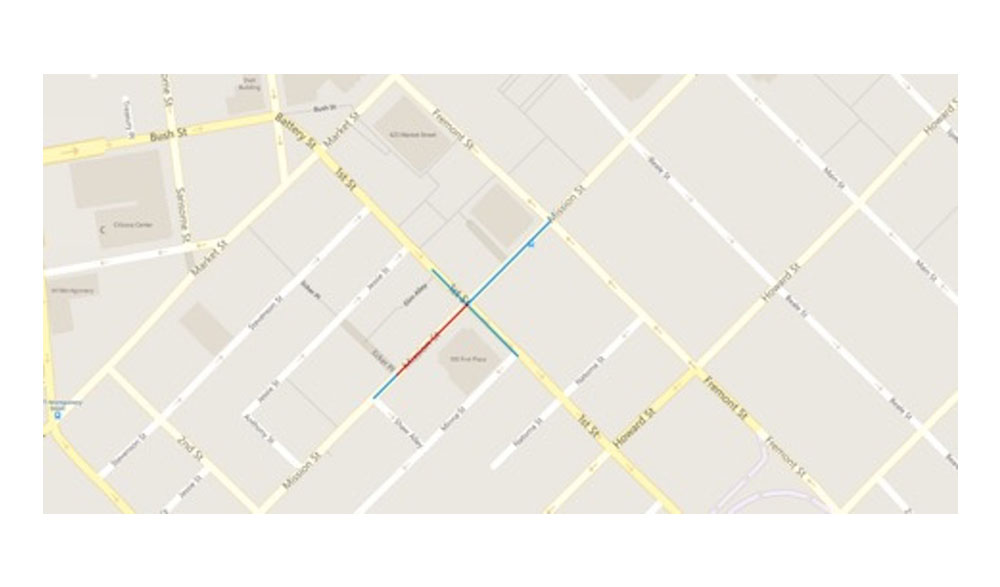
Once all EdgeRecord sets are generated, each source and target address range features are de-duplicated and stored in a Lucene index. Deduplication is required because each source address range to target address range edge record will be generated two times: once while generating edge records for source address range and once while generating edge records for target address range. Duplication will lead to double the memory size, and since we have a limited amount of memory on server boxes, we want to reduce the index size as much as possible.
Lucene index is then used as part of an API call accepting latitude and longitude. The call does a Lucene spatial search to query all the EdgeRecordSets with boundaries within a 1km radius of the given point (latitude, longitude). These EdgeRecordSets are then sorted by distance and the nearest point is selected. The selected point is the nearest intersection, and is what’s used to mark a non-disclosure property on a map. The below diagram illustrates an intersection for a given property:
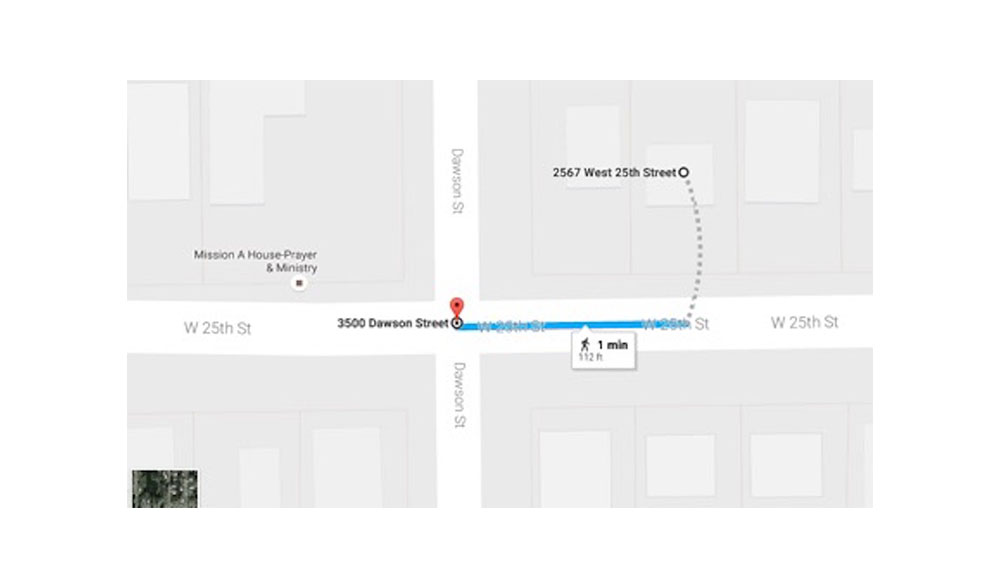
As a result of geocoding to the nearest intersection, we can ensure consumers see all valid listings in our maps, even if they are non-disclosure listings, helping to ensure they can easily find what they’re looking for.

