The Trulia data science team is a R&D team focused on machine learning applications, such as Text Mining, Natural Language Processing, Computer Vision, Spam Detection, Search Ranking, Recommendation, and more. As Trulia started moving towards Service-Oriented Architecture (SOA) providing all the fancy algorithms by APIs, we started looking for a technology that can help us efficiently release, test, and improve DevOps efforts. Eventually, we found the perfect tool for building service-oriented architecture, Docker.
Docker
Docker is an open platform for building, shipping, and running distributed applications with containers, which allow us to package up an application with all the parts it needs, and create a minimum runnable package that runs anywhere. Over the past year, Docker has been widely adopted by big companies like Google, Facebook, and Amazon. In fact, according to this survey, adoption of Docker has increased five times over the past year. Most companies are using Docker for their back-end development, and while we’re also interested in what Docker offers, we decided to use it in a broader way: deploying it within our data science team; and we are quite pleased with the outcome.
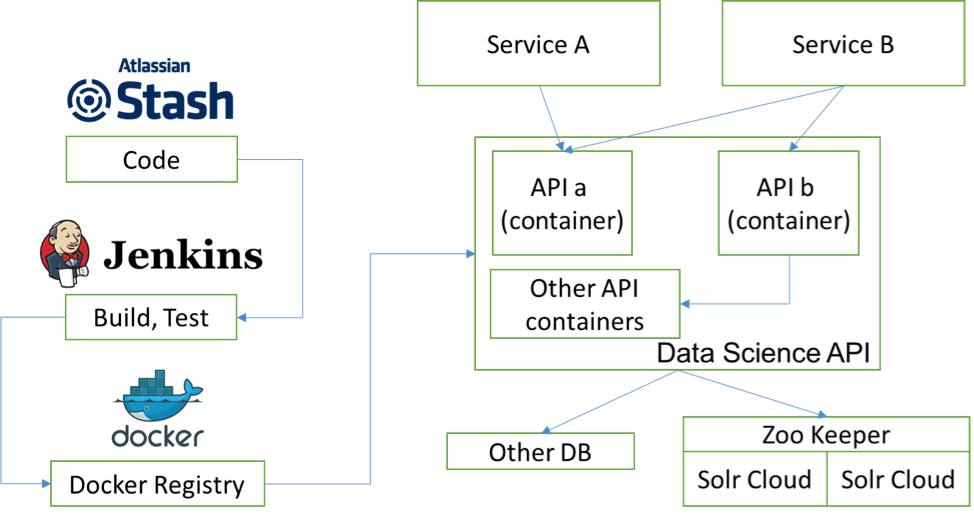
With Docker and Docker Compose, we can easily package our API with all its dependencies and caches, such as Redis, into containers. Since containers are very light and can run anywhere, alone with Jenkins, the testing and releasing process is seamless, and releasing is fast. In our practice, we found containers are rather stable, and even though they sometimes die, we can recover a container within a few seconds. Docker’s log analysis with ELK (Elasticsearch, Logstash, Kibana) is also very convenient as it ensures log collecting is fast, search syntax is powerful, and dashboards are easy to configure. These features dramatically reduce our data scientists’ DevOps work.
Why Docker for Data Science
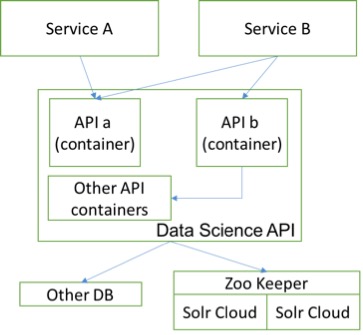
Real world machine learning pipelines are not always simply one clean component; a huge pipeline involves several modules. In Trulia’s micro-service architecture, different modules are taken care of by different people and deployed in different environments, such as on local servers or in the cloud, or a combination of the two. When working in a complex deployment environment like we do at Trulia, we needed to find a way to standardize every data scientist’s delivery to support faster deployment and ensure we can easily scale up, and Docker provides that.
Using Docker allows us to package our machine learning modules into containers and deploy them to any environment with ease. By having a pre-defined common interface between each module in the pipeline, the pipeline can be scaled to any size, and delivered to any environment without worry. This is very useful for groups working on a huge pipeline with various tech stacks and different languages, such as Java, Python, or R.
At Trulia, we are proud to be a full stack data science team providing end-to-end solutions, with every data scientist taking care of both researching and shipping our algorithms to production. Overall, using Docker helps us quickly build strong API architecture and quickly deploy models anywhere, which helps us deliver the best technology – and therefore experience – to our users.

