In previous posts, we shared how Trulia uses deep learning and image recognition to drive consumer engagement through applications like our homepage collections of homes and listing hero images. In this post, we will share how we deploy these models to production, and some of the challenges and design decisions involved in the process.
The lifecycle of any machine-learning or deep-learning model can be broadly broken down into three phases: 1) data gathering, 2) training and 3) deployment. We’ve talked about how we train some of these models, but training models is only part of the challenge, serving these models in production has its own set of challenges.
In our case at Trulia, our inference engine and the underlying hardware and software infrastructure need to support a large volume of traffic while being extensible, scalable and fault tolerant.
While building our system we had the following key features in mind:
- Machine learning as a service
- Decoupled API and prediction layer
- Scalable and fault tolerant infrastructure
- Extensibility: Support for multiple frameworks
- Optimizing performance for high throughput and low latency
Let’s look at each of these features in more detail:
Machine Learning as a Service (Service Oriented Architecture)
At Trulia, we deploy our deep-learning models as a RESTful API service. Serving machine-learning models as a service has several key advantages. First, deep-learning models often require dedicated hardware like Graphics Processing Units (GPUs) to accelerate processing. Abstracting the hardware and software dependencies of the models behind the service makes integration with downstream applications easy. Second, it allows our models to be easily usable across different teams and applications, while sharing the underlying infrastructure.
The service supports both synchronous and asynchronous requests, making it suitable for both real-time and batch processing workflows.
Asynchronous mode is useful for near real-time or batch processing workflows that can consume the predictions generated by the system asynchronously through pluggable callbacks like Kafka, Amazon SQS, Amazon S3 or a custom callback service, etc. For example, we use asynchronous requests with Kafka callbacks to stream near real-time updates of image tags to our image indexes that power applications like Trulia’s homepage or hero image project.
On the other hand, synchronous mode is ideal for low-latency applications that want real-time predictions for their inputs.
Decoupled API Layer and Prediction Layer
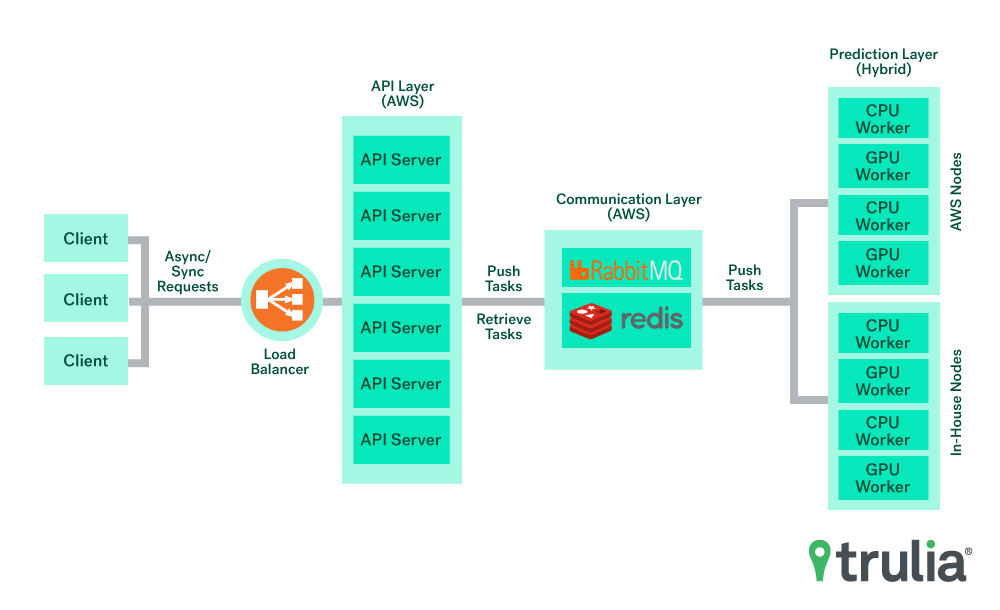
Trulia’s inference engine consists of two core components: The API layer and the prediction layer.
The API layer is responsible for handling client requests and directing them to the backend prediction layer that hosts machine-learning models to make predictions. The API layer and prediction layer communicate with each other using Celery, a distributed task queue that enables distributed processing of tasks across single or multiple worker servers. For our setup, we use RabbitMQ as the message broker and Redis as the backend for storing system state and task results.
The API layer is responsible for composing and pushing tasks to the job queue, while the prediction layer is comprised of workers that consume and execute tasks from the job queue.
The decoupling of the API layer from the prediction layer has several key advantages:
Abstracting Prediction Layer: The API layer helps to abstract away the prediction layer from the clients. This is essential to regulate the traffic to the prediction layer to ensure it doesn’t get overwhelmed and that the prediction resources (e.g. GPUs) are properly utilized. The API layer is responsible for parsing user requests and composing tasks for the prediction layer. This includes chaining and routing the multiple CPU/GPU bound tasks needed to complete the request.
Decoupling Responsibility: The API layer is built for high availability and low latency service to the clients, while the prediction layer focuses on managing machine-learning models and providing high prediction throughput.
Decoupling Infrastructure: The design enables the API layer to be hosted in a separate set of nodes with different software and hardware dependencies than the prediction layer. The API layer requires CPU nodes to handle concurrent requests while the prediction layer leverages GPU nodes to provide high throughput prediction. This enables us to horizontally scale each of these services independently as required.
Scalability and Fault Tolerance with Hybrid Infrastructure
Every day, Trulia receives millions of images as new listings hit the market. Each of these images need to be annotated by several deep-learning models before their attributes can be leveraged by downstream applications.
GPUs have been widely used for deep learning, as they provide significant performance improvements over CPU. To be able to process this scale of data and provide near real-time predictions, we have set up an in-house cluster of GPU machines for deploying these models.
We have found Nvidia Titan X (Pascal/Maxwell architectures) GPU cards ideal for our setup given their large GPU memory and compute power. At full capacity, our system can process more than 20 million images per day, even with a reasonable sized cluster.
As mentioned earlier, our setup helps us to horizontally scale our compute capacity by simply adding new GPU/CPU nodes to our prediction and API layers, while providing fault tolerance against node failures.
While there are a lot of cloud solutions providing support for GPUs, like AWS and Google Cloud Services, we have found the in-house cluster to be more cost effective for our use case, as our services are running 24/7.
However, in certain scenarios, like in the case of a sudden spike in traffic or in re-tagging images in our database when a new model is released (in tens of millions), we would like our system to seamlessly scale without impacting the performance of our existing applications. To achieve this, we have also added support for on-demand scaling with AWS Auto Scaling Groups, which allows us to spin up new AWS GPU/CPU instances to scale our infrastructure to meet the required capacity.
This hybrid architecture helps us keep the day-to-day running costs down with the use of an in-house cluster, while at the same time providing us the ability to efficiently handle high-load use cases when needed.
Extensibility: Support for Machine Learning Frameworks
At Trulia, we use several different kinds of machine-learning models and frameworks, both custom as well as open source. While building our inference engine, we wanted to create a generic core platform where different kinds of models can be easily deployed, thereby leveraging the common infrastructure and functionalities.
To enable this, we have created an abstraction that makes it easy for us to plug in support for new machine-learning frameworks and models while reusing common components. Currently, the system supports deployment of deep-learning models trained with Caffe as well as Gradient Boosted Tree models trained with XGBoost, with support for Tensorflow and others coming soon.
Models deployed on this system can be run in either CPU or GPU mode. The system supports multiple versions of the models to be deployed as well the ability to combine multiple models to form composite models or pipelines.
Optimizing Performance for Throughput and Latency
One of the key challenges while deploying deep-learning models is to ensure effective usage of hardware resources, GPU in particular, to maximize overall throughput of the system. This includes both proper utilization of the GPU memory, as well as making sure the GPU cores are kept saturated most of the time.
- Sharing GPU resources across Clients and Models
The system is designed to serve multiple models across different applications and clients at any given time. The prediction layer comprises several worker nodes each running one or more copies of the prediction layer, each capable of performing predictions for any of the supported models. Models share GPU/CPU memory and are loaded lazily, which means that GPU/CPU resources are only allocated when a model related task is first assigned to the worker process. Since multiple clients can be using our service at any given time, we wanted to make sure that compute resources are fairly allocated based on expected traffic and latency requirements of the clients. This is achieved by creating dedicated queues by either task, model or client type. For example, for lower latency synchronous tasks, we create queues with dedicated workers per task; while for high-throughput tasks, we define general purpose queues that are assigned a larger number of workers shared across multiple clients. - Decoupling CPU and GPU Processing
Every model prediction pipeline comes with its own set of operations. Each of these operations are different: some are I/O bound, others are compute intensive; some run on CPU, while others on GPU. For example, in case of our image recognition pipelines, the inputs are raw URLs which need to be first downloaded, preprocessed (resized, mean subtraction, etc.), make model predictions and then push the prediction results to a callback. While the preprocessing (download and resizing) and the post processing (pushing results to callback) operations are performed on CPU, the model predictions are computed by performing a forward pass on the GPU. Preprocessing operations like resizing can be significantly expensive when compared to time taken to generate model predictions on a GPU. Furthermore, I/O bound operations like downloading URLs and pushing to callback can be an order of magnitude slower depending on network latency. Executing these operations sequentially would severely impact throughput as the GPU would be sitting idle most of the time waiting for CPU operations to complete. To handle this issue, we consider operations in a pipeline as nodes in a computational graph (Directed Acyclic Graph), where each node (i.e. operation) could be individually assigned to execute in either CPU or GPU mode. This decoupling allows GPU worker threads to only process GPU bound operations without waiting on CPU operations, thereby maximizing GPU usage. By implementing model pipelines as disjoint linked tasks and using CPU and GPU queues each with dedicated worker instances, we see significant improvements in throughput.
Streaming and Serving Data
Once the predictions are generated by the system, the data is streamed to the callbacks specified in the request. Dedicated consumers listen to these callbacks and publish them to downstream data stores like HDFS, S3, Solr, Redis, etc., in real-time.
This data is also joined with other sources, like property metadata, either as part of a batch MapReduce/Spark job or in real-time and indexed into our data stores (e.g. Solr and Redis), which power our production APIs that surface this content to the front-end for rich consumer experiences. Note that the production APIs are different from our prediction APIs as they are serving live consumer traffic with static data, and have much lower latency requirements than the prediction service.
Deploying deep-learning models comes with its own sets of challenges some of which we have covered above. The system is constantly evolving as we continue extending it to broader applications, and prioritizing features to add based on immediate business needs. Stay tuned for more from us on this throughout the year.

