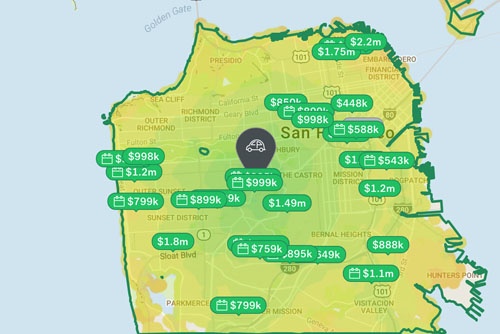
Finding the house is only half the journey in finding the perfect place to call home. It is also important to consider other variables like nearby amenities, crime rates and commute times. When it comes to commuting specifically, studies continuously indicate that longer commute times negatively impact our social lives and our overall well-being, and we’re finding that commute times are generally on the rise.
To help alleviate the stress of discerning how long a commute might be from a home, Trulia offers a commute tool and heatmap. Together, these features give consumers a visualization of the time it takes to reach their desired destination from a given origin (i.e., the home they’re interested in). Moreover, the commute times can be calculated for a specific mode of transportation (e.g., car, public transit, biking or walking). Under the surface of our commute heatmap is a computationally intensive API, which we’ll dive into in this post.
How the API works
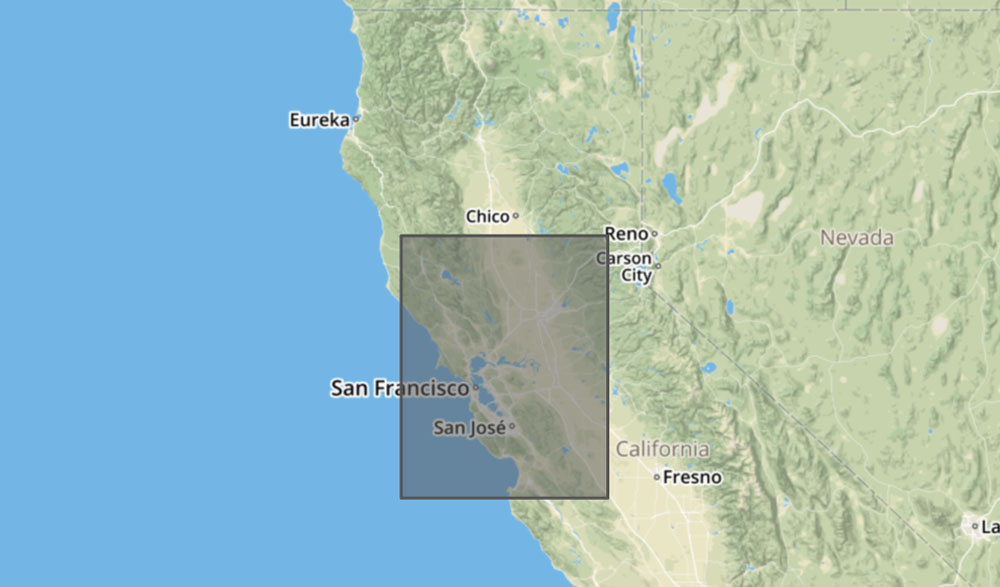
At its heart, Trulia’s commute API runs a modified version of Dijkstra’s algorithm to calculate the shortest path between points within our commute data (underlying transportation networks), which we represent internally as a collection of graphs. Each graph is stored as a binary file encapsulating a 3-degree by 3-degree segment of the United States (see below).
The system offers several distinct ways of describing commute times, such as point-cost, isochron and tile. Point-cost, the most fundamental of our calculations, returns the amount of time it takes to get from an origin coordinate to one or more destination coordinates. Isochron returns a set of geoJSON polygons which encapsulate the reachable areas from an origin under a user-provided time limit. Lastly, the tile calculation provides the cost-per-pixel information necessary for the front-end team to render Trulia’s commute heatmap.
How we scaled
Trulia put the first version of its commute API into production several years ago. The system ran smoothly, but as time passed it became clear that we would need to scale to serve not only Trulia’s consumers, but eventually its sister sites’ consumers, too (plus new platforms – we recently rolled the commute heatmap out to Trulia’s mobile apps). For us to scale, while simultaneously lowering the average latency per request, we needed to rethink both our code and our infrastructure.
Code improvements
Our original commute system used a disk-based cache; however, the cache quickly became a bottleneck when traffic spiked and too many resources were wasted on cache management. We removed the cache in order to avoid passing the entire graph state from the routing process to its parent process. By passing only the costs of the nodes of interest rather than the cost of every reachable node, we could shrink the interprocess data handling from around 150MB down to about 60KB per request. Another massive latency reduction came from the migration of our binary graph files to memory; however, moving all 200GB of binary files to memory was not possible with our in-house servers, so we needed to migrate our system to AWS.
Infrastructure improvements with AWS
One great benefit of AWS is its wide selection of EC2 instance types. The R4 instances worked particularly well for the commute API by offering more than enough computational power and memory. Another benefit of the AWS environment is the ability to use auto-scaling groups to react to the ebb and flow of traffic patterns. In the original API, we had a fixed number of worker machines behind a load balancer. Now, we can automatically increase or decrease the number of worker machines behind our ELB when either the latency or average requests per minute exceed a certain threshold. On top of all these conveniences, we can now rapidly develop our infrastructure due to our automated deployment via Packer and Terraform.
How well it scaled
It took a considerable amount of time and research to determine where to optimize and where to compromise, but in the end, we managed to scale to Trulia and two of its sister sites while reducing the average latency per request from about 500ms down to 200ms. The move to AWS might have been an increase in real estate price for us, but the quicker commute sure is lovely.

