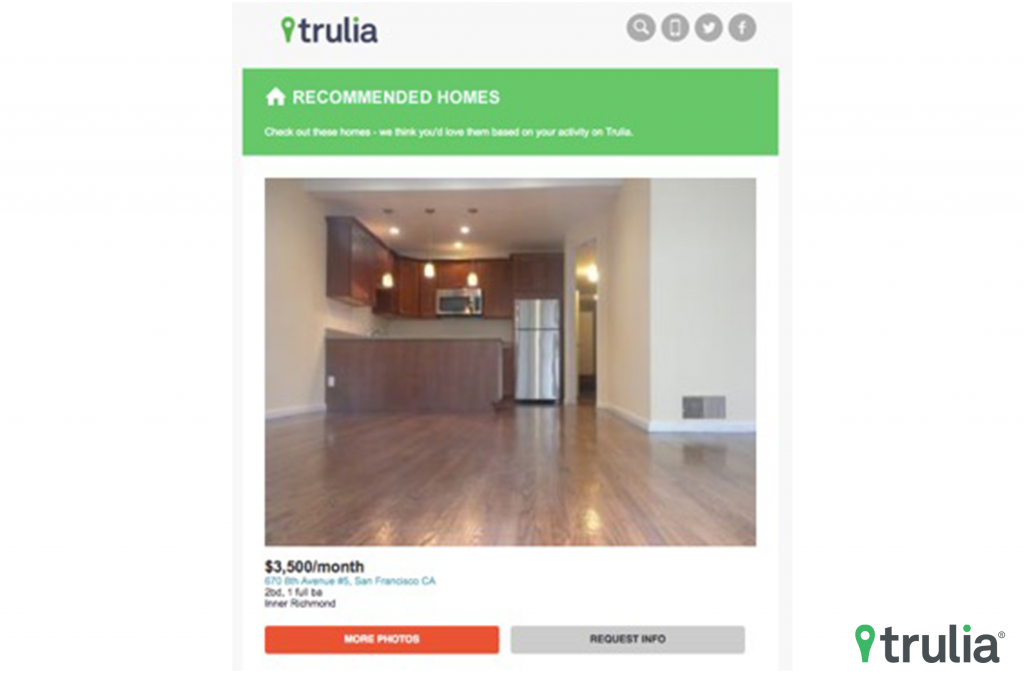
Traditionally speaking, finding the right home is often a long, stressful, and tedious process. But, Trulia makes it easier by giving consumers details and unique insights on the homes they’re interested in. To simplify the process even more, we’ve built a recommender engine to ensure consumers are always seeing what’s relevant to them. Here’s an inside peek at how it works:
Getting Setup
From our internal logs of user browsing behavior data, we can infer whether a user likes a property (e.g. user sends an inquiry or saves the home) or doesn’t like a property (e.g. user quickly bounces from the property page). We collect all user-property interactions and form a giant bipartite network of users and properties, where each edge is labeled positive ‘+’ (i.e. user likes the home) or negative ‘-’ (i.e. user doesn’t like the home). This gets us properly setup to formulate the problem of recommending the most relevant properties to a given user as a network link prediction problem: given a target user-property pair, we need to predict whether the edge will have a positive or negative interaction.
Wedge Count Model and Machine Learning
To address that network link prediction problem, we apply the wedge counting method developed from my prior published research in applying network science for building a recommender system. For a given user-property target pair, we can simply enumerate all possible three-edge wedges that start from the target user and end on the target property. Since each edge is either ‘+’ or ‘-’, each wedge belongs to one of eight possible wedge configurations (see Figure 1). We then record the counts of wedges for each configuration accordingly.
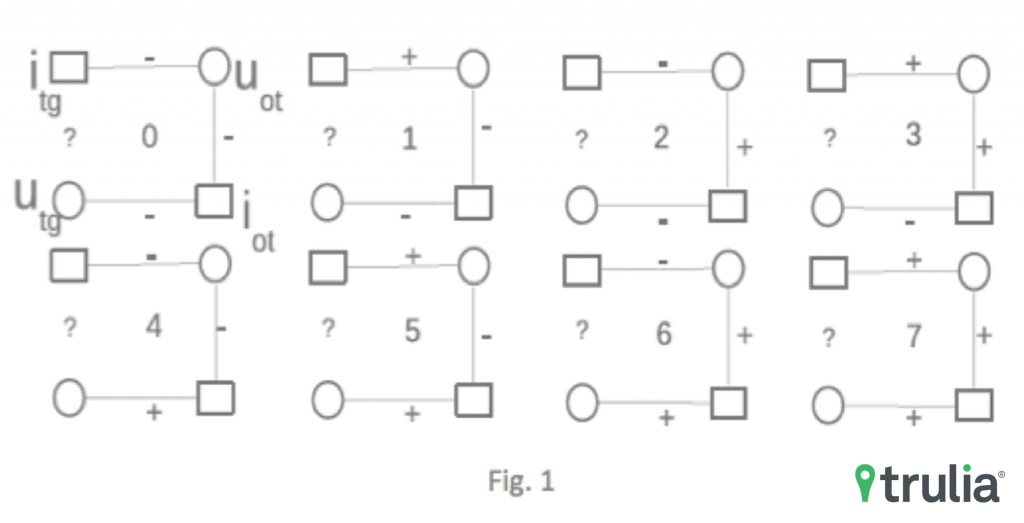
We can now build the data matrix for training a machine learned model: each row represents a user-property interaction from training date with a truth label of ‘+’ or ‘-’; there are eight feature columns with each feature being the wedge count of each of the eight configurations from interactions log data prior to training date. We implemented the wedge counting method in Hadoop/Java, processing a bipartite network with tens of millions of user nodes and millions of property nodes. Training a gradient boosted logistic regression model in Python, we obtain an AUC in the .90+ range from an 80/20 split for train and test. The most interesting result here is that the logistic regression coefficients are the highest for configuration one and four from the above figure, which means that what users don’t like gives us much stronger signal on what they and other users do like.
Deployment
Since going live by powering our email programs, the recommender engine has worked to deliver more accurate recommendations to more users. We’re just scratching the surface of what we can do and we’re excited for what’s to come!