Last year, Trulia’s personalization team turned to the Lambda Architecture in order to continuously add new features to our generated user profiles, even on old data, while having a near real-time view of all our consumers’ interactions with Trulia. While it’s a great methodology to capture and organize data, implementing the real-time part of Lambda Architecture was not without its headaches. Here’s a look at some of the complications we saw and how we solved them, but first, let’s recap:
Recapping our user model and its complications
Our personalization team’s user model supports both registered and unregistered users. Each unregistered user has exactly one Id that we call a Secondary Id, which reflects the different platforms they are accessing our site from, i.e.: web, mobile web or apps. Registered users have one Login Id and one or more Secondary Ids, since they may have accessed our site from more than one platform. In order to serve our users well, we need to merge all the activity from all Secondary Ids under the user’s Login Id, and we need to do that fast and as near real-time as possible.
The complications in our real-time layer rise from the fact that we discover the linkages between user Ids and Secondary Ids, both while the batch layer is being calculated (with information only as recent as the day before) and in the real-time layer (where information is very recent). So, we have cases where a linkage we thought was correct in the batch layer has now been broken, i.e. a user we thought was unregistered has decided to register today, or a Secondary Id has now been discovered to belong to another user. We needed to plan for these cases and make sure the eventual User Trait reflects the state of a user as of right now.
One easy, but naïve, way to solve these issues was to pause the real-time when the batch layer was done computing until all user linkage discrepancies were solved. The issue with this approach is that while the resolution process is ongoing (and it usually takes at least a couple of hours), we are unable to process any new user activity. Meaning, we would then need to wait for some time until we were all caught up with traffic before we could direct the clients using the UserTrait to the newly created epoch.
Our real-time implementation
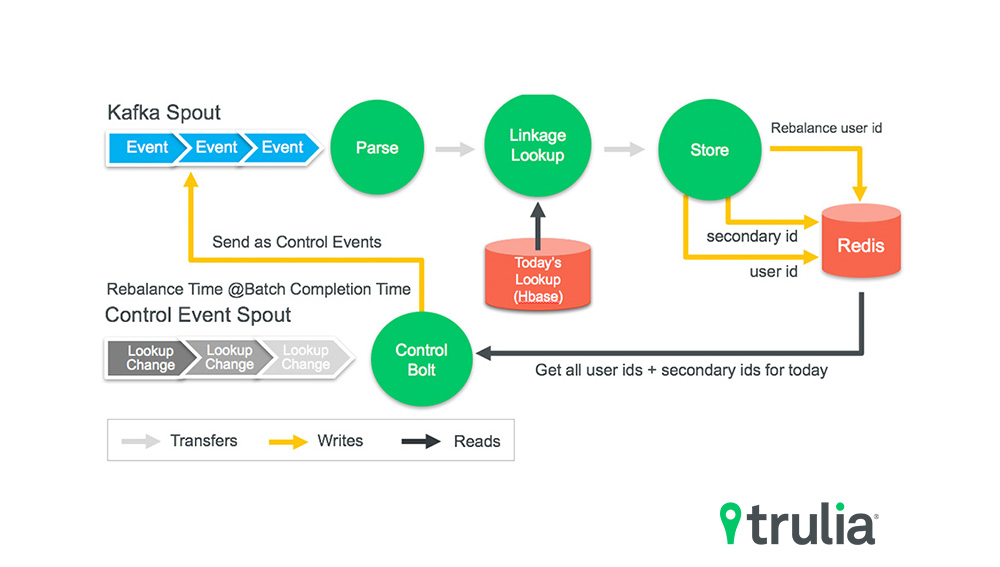
Clearly, that was a less than ideal solution, so we decided to go with a more complicated, but much more efficient, real-time architecture. In this new architecture, we always update the partial real-time UserTrait twice: once using what we think is the user Id with the information we have as of now, and once more using the Secondary Id the user event has associated with it. Of course, for unregistered users we only have a Secondary Id available so for these cases we only update once. We also save any new linkage we discover in the real-time layer in our real-time cache. This way, any new event for the newly discovered linkage gets correctly reflected no matter where it lands in our real-time Storm topology.
As soon as the new batch epoch has been completed, we go through what we call a rebalance. During this rebalance we do several things:
- Switch the user lookup table the real-time layer is using to the one just created by the batch layer. This ensures that new user events will use the most up-to-date batch information for user linkage.
- Calculate the delta of user linkage between the newly calculated and previous epochs. We then pass all these users, along with the changes we have observed (new, changed or deleted linkages) again through the real-time layer, ensuring that it now correctly uses the most up to date linkage information. We call these events Control Events and we have a special, dedicated bolt that only comes into play during the rebalance phase.
- Pass every user we have seen so far in the day in the real-time layer, ensuring that we correct any linkages the real-time may have wrongly used up to now. We can now reconstruct the correct UserTrait for that user as we have the partial UserTrait’s for all Secondary Ids the user Id is now linked with.

Using this architecture, we can switch to the new Lambda epoch as soon as we are done with our rebalancing. There’s no need to pause the real-time layer, nor wait until it has caught up with any traffic. The real-time layer is ready to serve real traffic, right away. Here’s how we transition from epoch to epoch:

The approach we decided to take was much more evolved and required more effort in coding, Storm bolt coordination, and extensive QA and real-time checks to ensure everything worked as expected. But it paid off, as we are now able to seamlessly transition from epoch to epoch without any pauses or compromises in correctness. As a result, we’ve successfully completed our Lambda Architecture implementation efforts.

