
Trulia works hard to help consumers find the right home and neighborhood for them. As part of that effort, we’ve made investments and improvements in how consumers can search for and save homes, and stay-up-to-date on the status of those homes, among other things.
Saving homes and specific searches is one of the best-loved features for home-seekers because it helps them move fast in finding their home. How do we do this? We created an application called percolator. Percolator allows us to find and share relevant updates with consumers on new homes that match their search criteria and status updates on listings they’ve saved.
As Trulia’s data continues to increase, we redesigned and created a next generation percolator application (percolator-NG), which we’ll talk more about in this post.
Percolator-NG is real-time, scalable, performant, running in AWS (Amazon Web Services), and easy to expand for different and new features. Percolator-NG also reads consumer behavior data to make matches on non-saved searches. The app then supplies these matched data as an input to our email system, which notifies consumers about different property events. On a daily basis, percolator-NG is matching hundreds of millions of consumer search criteria.
Approach: Reverse Lookup
Percolator-NG performs reverse lookup to match new property and property updates to consumer search criteria. In this approach, we index the consumer queries as documents and use incoming properties or updates as queries to this new index, so we can find out which consumer search criteria matches the incoming properties. For example, if a consumer saves a search for $700K-$950K price range with 2-3 bedrooms in San Francisco, it will match to a new property in San Francisco with 3 bedrooms and a price of $800K. Once the match is made, the consumer will be notified about the matched property.
Why do we perform reverse lookup? Matching properties per consumer criteria is inefficient, since consumers perform millions of searches a day on Trulia. Doing the reverse – looking at different property events and using it to match to search criteria – is much faster, scalable and more effective.
Technical Bite
Percolator-NG is running in AWS and it makes use of different technologies, like SolrCloud, Application (Java/Spring based), Amazon ElasticCache, Spark, SQS, SNS and S3. The Java Application is divided into two modules: 1) Reader and 2) Writer, which are running in EC2 with attached Auto Scaling group (ASG).
Writer is responsible for updating the data in SolrCloud through batch processing and keeping consumer search criteria data up-to-date. Reader uses core logic to form the complex queries based on input events and perform the reverse lookup in user criteria (Solr) to find out interested users.
Reader (architecture shown below) is a spring-based Java application, which triggers processing on each qualified property event and performs percolation. This is where we form Solr query from input event and extract matched user search criteria document from Solr using SolrJ and Solr Query Stream.
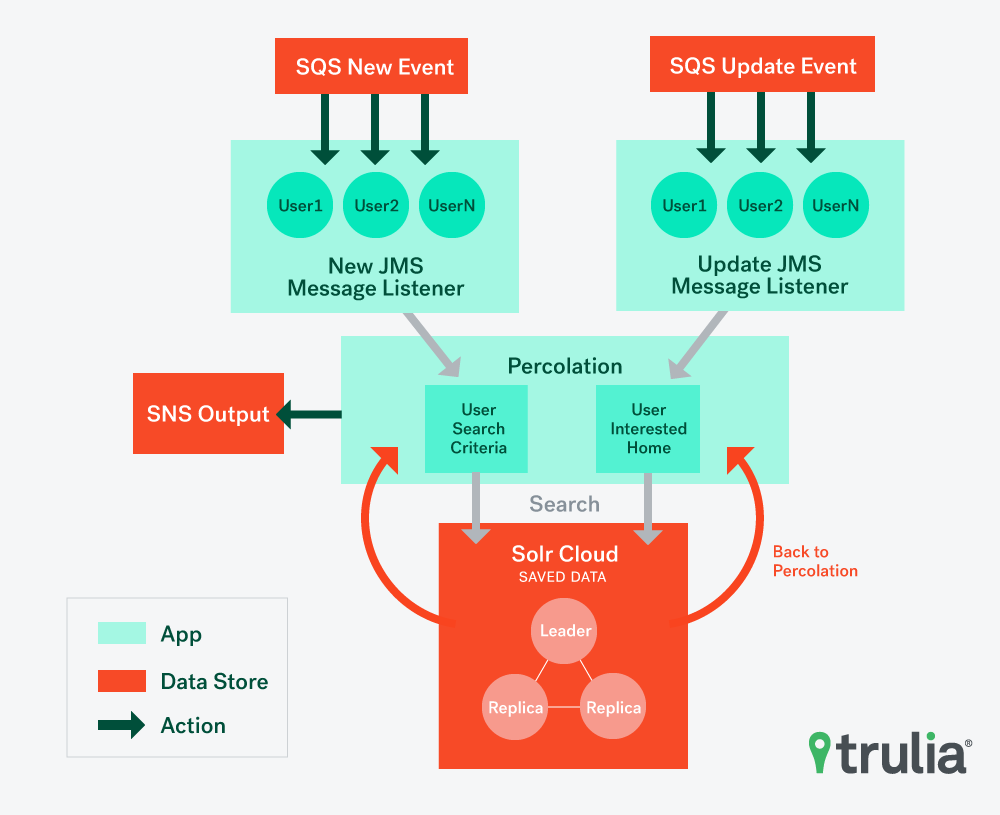
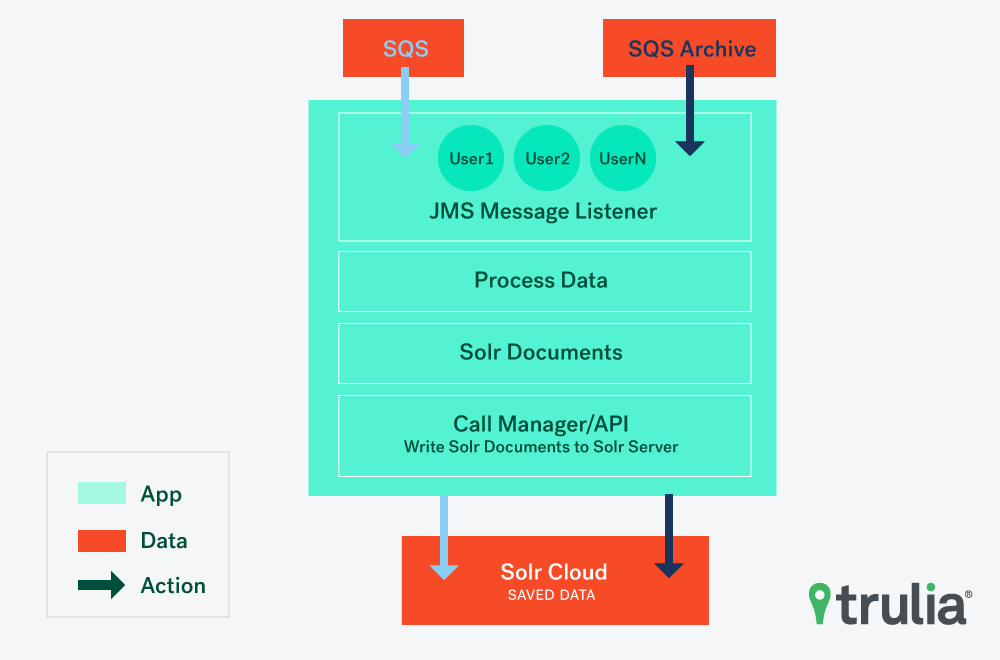
Who is using Percolator-NG?
Percolator-NG output is consumed by the Trulia Communications Team, Footprint Team and Data Science Team. As percolator-NG is publishing output data to AWS Simple Notification Service(SNS), we can simply create different AWS Simple Queue Service(SQS) subscriptions to the same SNS topic. This allows multiple teams to consume the same percolator-NG data at the same time.

