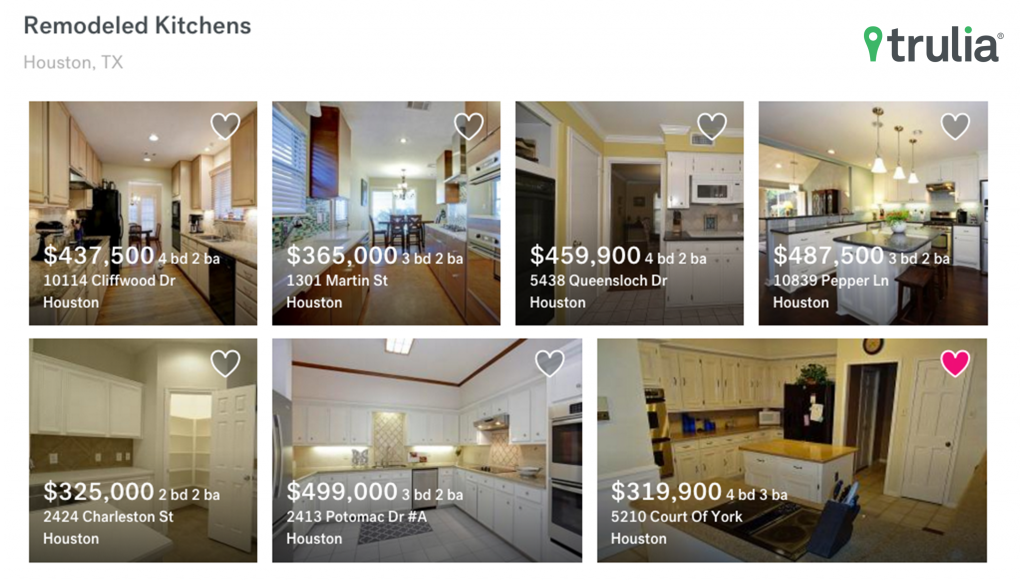
In my previous post, I explained that by understanding real estate photo content Trulia is providing consumers with a better visual browsing experience. Trulia receives more than a million new real estate photos every day, and categorizing them into well-known home features is the first step towards enabling this experience.
In this post, I’ll describe how we organize photos into rich collections, allowing consumers to go beyond standard search filters, like number of beds, baths, price range, etc., and enable discovery by home features such as “infinity pools” or “kitchens with granite counters and white cabinets.” Think of the experience as similar to that of Houzz or Pinterest, but for actual homes on the market.
Our approach to automating these collections required three main components: A Real Estate Vocabulary, a Visual Model, and a Text Model.
Building the Real Estate Vocabulary
The first step in building these collections was to understand what features are interesting in the real estate domain. Instead of building this vocabulary of home features by hand, or by using help from home design experts, we use text mining and NLP to automate the process.
Every property listing on Trulia comes with a rich textual description with phrases describing home features like “infinity pools,” “granite counters,” etc. We use n-gram language models to find the most commonly occurring phrases in a corpus (A.K.A., property descriptions). This approach provides a good baseline, but may often contain phrases that are frequent but do not represent a real estate term, or phrase.
So, what makes a good “Real Estate Phrase?” We need phrases that not only appear frequently (i.e. have high “Phraseness”), but that are also novel to the real estate domain (i.e. have high “Informativeness” or “Real-Estate-ness”), like “infinity pools.”
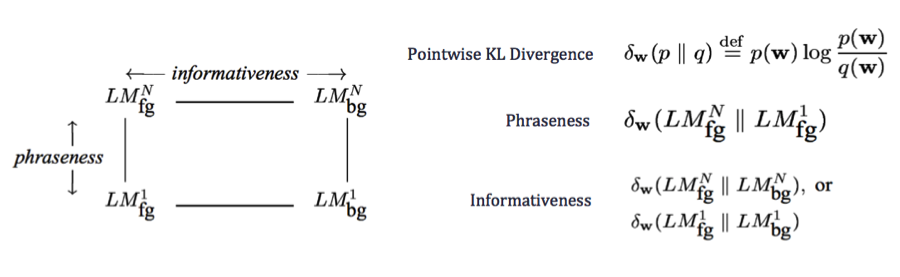
Figure 1: Phraseness is defined as the KL Divergence between the N-gram and unigram language models (LM) of a corpus while Informativeness can be computed as the KL divergence between the N-gram language models of the foreground (fg) and the background (bg) corpus. Refer to Tomakiyo et al
Following a similar approach as Tomakiyo et al, we use property descriptions as the real-estate corpus and Wikipedia as the background corpus, we rank each phrase as a linear combination of the Phraseness and Informativeness scores and use the top scoring candidates as our real estate vocabulary. Post-filtering is done to filter out noisy phrases or compress duplicates.
Building the Visual Model
Our image recognition engine uses Convolutional Neural Networks (CNN) as well as traditional Bag of Visual Words Models (like Fisher Vectors) running across a distributed gpu/cpu cluster. We use caffe deep learning framework to train our CNN models on Titan X GPU cards (more on our image recognition engine in a later post).
Ideally, we’d want to build image recognition models that could visually detect most features defined in our vocabulary, such as scene types (e.g. cellar), objects (e.g. chandelier), textures (e.g. hardwood), etc. While CNN’s have been successfully trained on thousands of categories, this often requires a huge amount of annotated data, which can be expensive and time consuming to collect. Furthermore, photos often have cluttered scenes that may obscure features like objects and textures, making it hard for visual models to detect accurately.
However, a majority of the photos that appear on Trulia can be categorized into a fixed set of scene classes. And, training data for certain classes like scene types can be collected easily when compared to labels for objects or textures, which may often require a human to perform multiple passes over a photo or draw bounding boxes. Therefore, instead of training visual models across our whole vocabulary, we train accurate visual models where sufficient data is available.
So, how do we annotate other features like objects, textures, etc.? We exploit the fact that each photo can be loosely associated with a potential set of candidate phrases in our vocabulary extracted from the property description. Next step was to build a model that could map a candidate phrase to a photo by using the knowledge provided by the visual model.
Building the Text Model
We want to understand the semantics of different phrases that appear in our real estate vocabulary and how one phrase relates to the other. This is useful in two ways: First, it helps us to refine our vocabulary and improve recall on text queries. Second, it provides us a way to define a mapping from the text domain to the visual domain. For example, we would like to know that “balusters” are associated with “stairways,” and “bicc” and “built in china cabinets” mean the same thing.
One way to learn these semantic and syntactic relationships among words is through Distributional Semantics, which states that words used in the same contexts tend to have similar meanings. This hypothesis lends itself pretty well to the kind of text found in property descriptions where related phrases often co-occur in similar contexts. Consider this snippet from a property description:
“Kitchen is equipped with stainless steel Whirlpool appliances including microwave and dishwasher”
One way we model these relationships is using word2vec. Introduced by Mikolov et al, word2vec tries to learn word embeddings (dense vector representations) such that words that are related to each other are closer in this vector space compared to words that are not. We train these word embeddings using the Skip-Gram model with negative sampling and dynamic window of size 10.
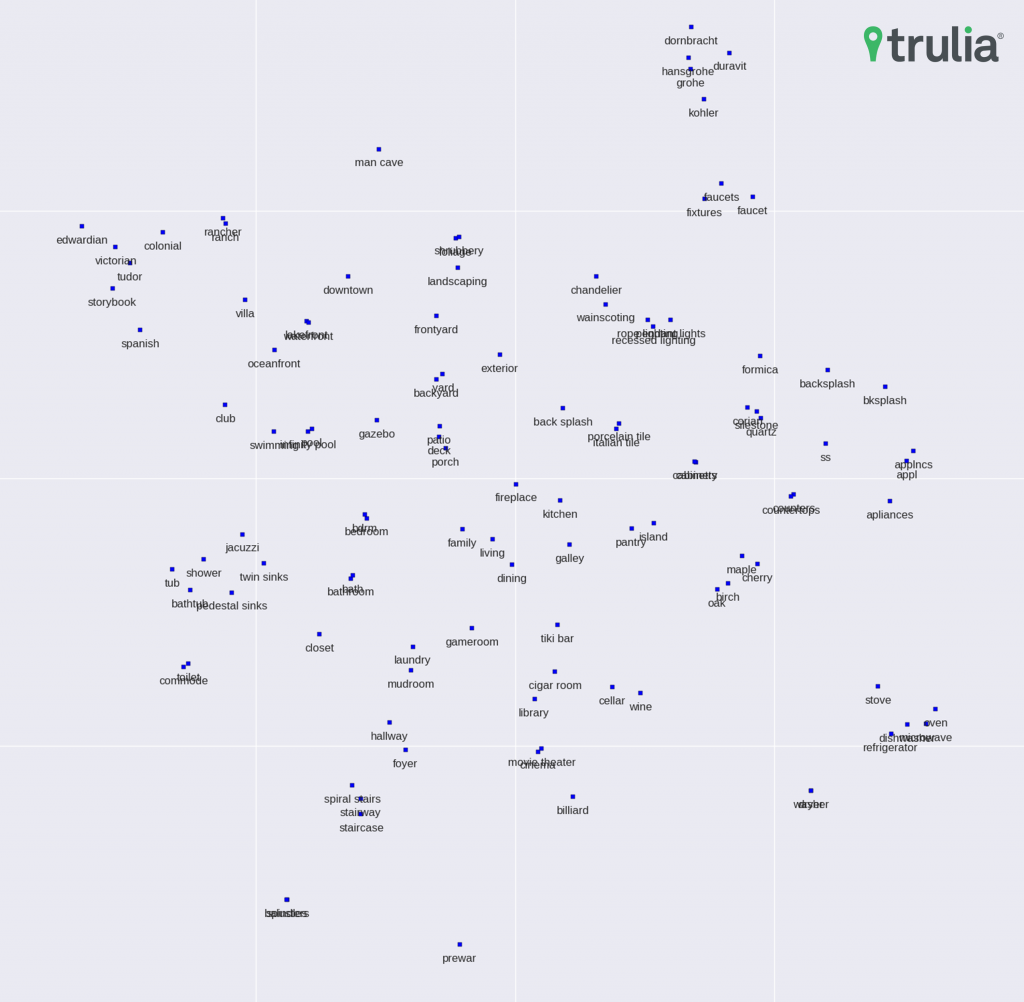
Figure 2: t-SNE 2D embedding of real-estate word vectors. Note how semantically similar words (like synonyms, misspellings, etc.) are closer in the embedding space and how semantic relationships among words also correspond to visual co-occurrence.
Bringing it Together – Knowledge Transfer and Zero Shot Learning
We now have all the necessary components to generate our photo collections. We use the vocabulary to extract candidate phrases from property descriptions and the visual model to generate the visual labels for each photo. Then, the word-embedding model is used to score each candidate phrase based on the similarities of the phrase embedding and the visual label embedding. The collections are then served via a search index.
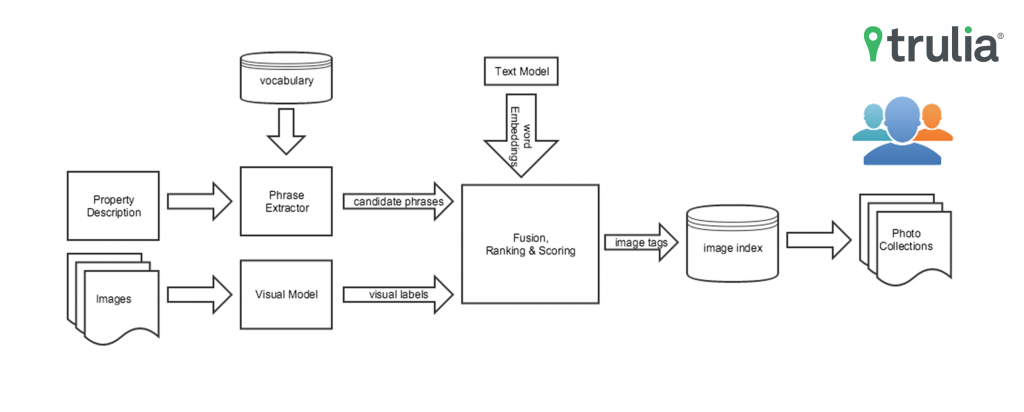
Figure 3: Workflow for generating photo collections. Combining knowledge from the text domain to the visual domain allows us to annotate our photos with features without explicitly training a visual model for that feature. This can also be referred to as zero-shot learning or learning without examples.
At the time of this post Trulia has more than 40 Million annotated photos (for on-market properties) in its collection that are being served to upstream applications and enabling consumers to discover homes by features of their interest. Furthermore, this data is enabling our product teams to enhance the product experience by customizing how photos are displayed across Trulia, and even personalize it to the visual taste of each consumer.
If you’re interested in hearing more, check out my discussion on this topic at Text By The Bay 2015.

