Don’t you just love logging on to Netflix and seeing suggested movies that you know you’d actually enjoy? Or, how about those spot-on recommendations when you visit Amazon? We love the personalization too, which is why we work to ensure that experience at Trulia.
The Trulia personalization team processes an ever-increasing body of user interactions to create instant, on-the-fly customizable views of our pages, so users always see the most relevant content to them. We started this effort last year by processing users’ daily interactions, and creating a personalized profile for each user with the aggregate metrics we thought were appropriate or feasible at the time. At the end of each day, we’d calculate the aggregate of what we learned about a user over the course of the day and merge it with the information we already had stored for them.
The problem with this approach became obvious once we realized it wasn’t possible to add new metrics to existing profiles because we weren’t storing detailed information about the interactions. This meant we were missing out on information and opportunity. For example, there was no way to find out if or when someone had opened an email from us, since we never saved any detailed information about that particular interaction in our stored aggregate.
Lambda Architecture to the Rescue
To create a truly personalized experience, we needed to change course and try a new methodology to capture and organize data. We needed a solution that would enable us to recalculate full user profiles by applying the latest and greatest of our code to the full body of events we had accumulated over time. We needed it to complete as fast as possible, while at the same time allowing us to query the latest profiles we had available, and get information back that was updated as close to real time as possible. Enter, the Lambda Architecture.
Trulia’s Lambda Architecture
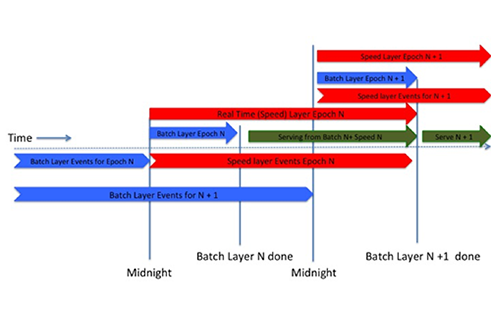
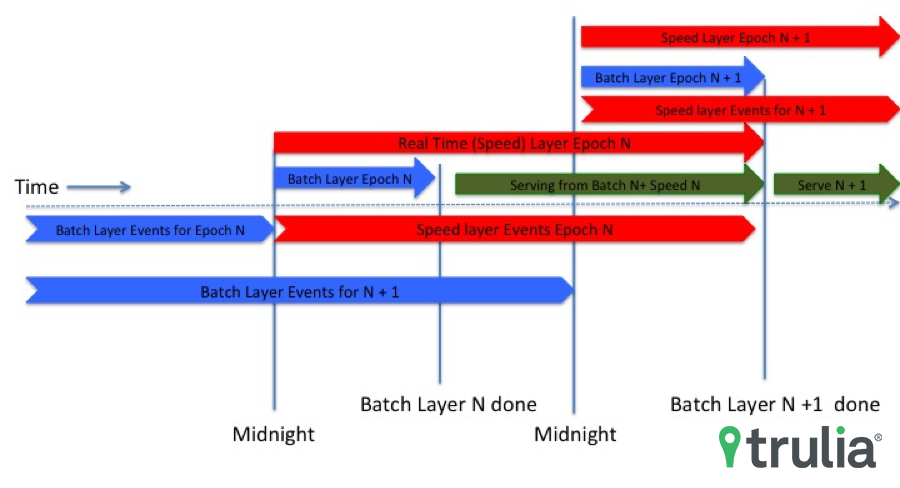
As we were preparing to implement the Lambda methodology, we started by saving every user interaction individually on HDFS, partitioned by hour and day, and once we started saving our immutable master dataset, we were ready to build our implementation of the Lambda Architecture.
After implementing our immutable master dataset, we began calculating each user profile at the end of every day by applying the latest version of our code to every interaction we accumulated up to the previous day. This became what is now our Batch layer, and it’s implemented in Scalding and Scala and running on Hadoop over YARN, with the calculated results stored on Hbase. While this calculation is in progress (it currently takes about six to seven hours to complete), our Speed layer picks up the slack by starting the exact same computation, but in real-time and only on the user events that have started coming in after midnight of that day. Our Speed layer is a Storm topology using Kafka as the streaming delivery mechanism for the inbound events. Once the Batch layer is done, we have what we call a new Epoch available, which is basically a fresh, complete set of user profiles calculated from our entire body of user events. We then start serving every request for a user profile by merging the information we have for that user in the newly created Epoch’s Batch and Speed layers. The result is an almost up to the second accurate depiction of the user interactions with Trulia.
Benefits
Applying Lambda Architecture at Trulia allows us to continuously add new features or fine-tune the ones we already have and apply them retrogressively to our full dataset. This means the more consumers interact with our site, the more we learn, and the more logic and code we can add to our master dataset to ensure more accurate personalization.

