
This post is a continuation of our series about paying down technical debt and re-architecting our platform. You can read the introductory post here: Paying Technical Debt to Focus on the Future.
As mentioned in our previous article, 2018 is the year Trulia Engineering is building a new scalable architecture to enhance performance and functionality, while boosting developers’ productivity and ease of deployment.
We’ll have more to share about this project overall, but I’m going to dive into one of the technologies that we decided to adopt as part of our new architecture: GraphQL.
Sometimes called “a query language for your API,” GraphQL is an alternative to the REST architectural style that allows clients to request the data they need, using a clear and self-documented interface.

Sample of GraphQL search using Graphiql
Why GraphQL
What persuaded us to try and, later, introduce this technology into our architecture were some of its promised benefits.
The appeal is evident if we look at the interaction between client and server. First of all, via GraphQL, clients are able to request specific objects and specific fields and have only that subset returned in the response, without extra fields that are not needed to build that particular UI component. While an API schema is usually dictated by whatever “backend” team owns the service, the GraphQL schema is instead client-driven and designed to meet client requirements, making it much easier to develop the client. Also, from the client perspective, GraphQL is a one-stop shop to retrieve data from all the different services that sit behind the scenes.
Another advantage of GraphQL is the ability to decouple clients and services so they can both evolve at different speeds and be refactored without impacting each other. This means that you can break down services into microservices without clients being impacted, which is a great upside in our case, given our strategic focus to break our monolith and migrate to a microservice architecture.
Last, but not least, documentation comes “for free,” which is a dream come true if you ask me!
Implementing GraphQL at Trulia
The first implementation of GraphQL at Trulia happened during a recent Innovation Week (hackweek). The prototype we came up with, and its reception from other developers at the company, inspired us to build a full-fledged implementation.
In Trulia’s new architecture, GraphQL decouples our web applications and mobile apps from our backend services. Both web applications, which we refer to as Islands, as well as Mobile iOS and Android apps, fetch data from GraphQL, all sharing a common interface to the data.
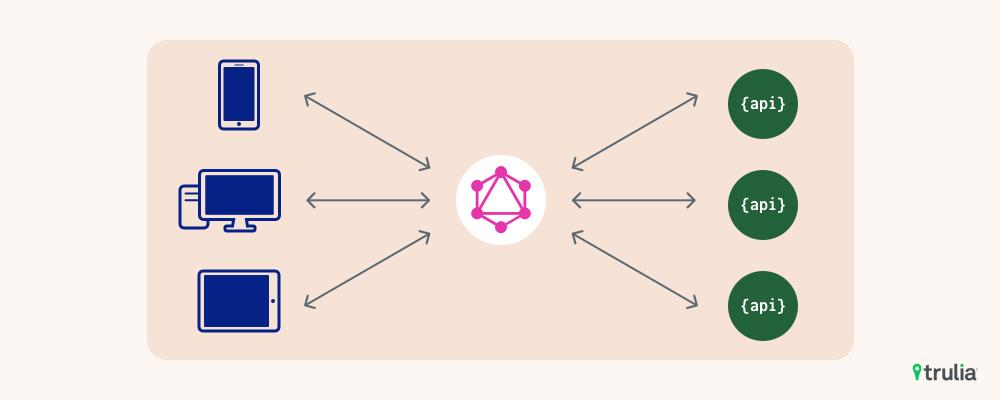
GraphQL as middle-man between clients and APIs
Trulia GraphQL Codebase Setup
One challenge we faced when we started exploring GraphQL was how to set up our codebase. While there are numerous implementations of GraphQL in a variety of languages, after our initial experiment with a Java implementation, we opted for Node.js partly because it’s a language everyone who works in the UI must know and partly because we found the community support to be superior. We develop all of our GraphQL code in TypeScript.
Having decided on the language, we had to answer questions about the code structure: will the code be in one monorepo or split into multiple source repositories? How could we limit conflicts arising from various teams making changes to the schema?
While we had questions to answer, one thing we knew for certain was that we wanted to ensure several teams could work simultaneously, rely on a common infrastructure, and easily collaborate with each other. So, after some trial and error, we decided to split up our code into two separate codebases: one for the schema and one for the service concerns, like logging and error handling. We chose to divide the schema into data sources and dedicate a folder to each data source. Our folder structure looks more or less like this:

The file structure of each data source is standard and it’s composed of the following:
- Resolver: Function that receives the GraphQL query with its arguments and uses the service(s) to retrieve the data.
- Service: Class that queries the connector to get raw data from external backends and returns a model to the resolver. The service is the glue between the connector and the GraphQL types.
- Connector: Layer on top of backend service. The connector is the piece of code that links a GraphQL server to a specific backend (a REST service, in our case). Each service will have its own connector. Other than connecting the GraphQL server to a backend, connectors should also:
- Batch requests together when needed
- Cache data to avoid extra requests
- Log information about data fetched
- Model: Interface that describes the GraphQL types. It can contain utility methods to map raw data to GraphQL types.
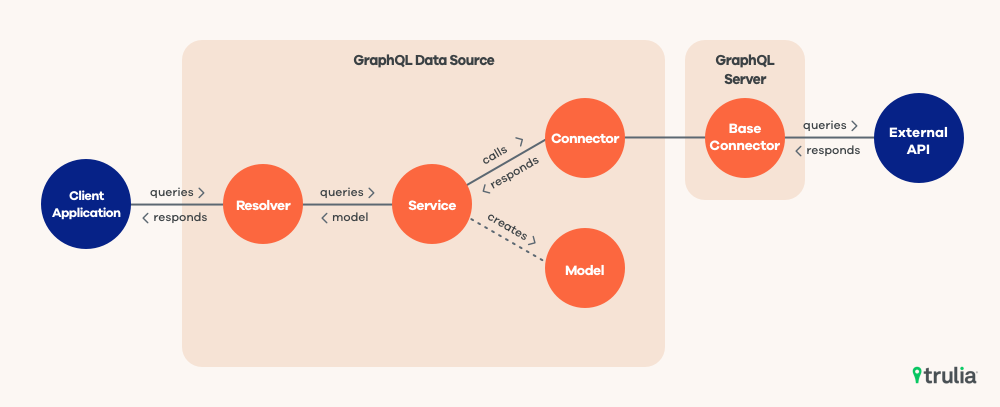
GraphQL data source structure
Something that we’re currently investigating is splitting up our GraphQL data sources into separate repositories and employing schema stitching, which creates a single GraphQL schema from multiple underlying GraphQL services. We believe that the explicit separation among data sources could improve team independence even more.
Key Learnings
Overall, GraphQL is a great choice for Trulia and other companies moving to a microservice-oriented architecture, but at the same time wanting to minimize the development time spent dealing with the complexity that this type of architecture tends to introduce.
We found that being able to fetch only what’s needed, and in the format that is most suitable, greatly benefits developers working on the UI components. They can now focus solely on the new feature they’re building or the improvement they’re making, instead of spending time wondering which API serves the data they need or how the response schema looks.
At the same time, developers working on the microservices “behind the scenes” can focus on building and maintaining a readable interface. The requirements of a specific user experience or feature are abstracted by the GraphQL schema, which clearly specifies the data that the service must produce.
As of today, we have two islands in production that leverage GraphQL – including our newest product, Trulia Neighborhoods – and we’re tirelessly monitoring and collecting metrics. Our goal is to keep tuning performances and improving our GraphQL platform, adding features and capabilities that will make developers’ lives easier. Stay tuned for more from us about this project!

