Previously, we shared a high level overview of our Personalization Hub and how we use Lambda Architecture at Trulia. An important part of both personalization and Lambda Architecture is real-time event tracking. Historically, we used a tracking pixel, which would be ingested and processed with a daily batch cycle, making this data available once a day, many hours after an event has occurred. However, to understand a user’s behavior in real-time, we needed to source events in real-time and the batch delay would be unacceptable for our system. Additionally, in order to receive events in real-time, it required collaboration with many different teams within our organization, which would also take more time. Thus, in order to understand a user’s behavior in real-time, we needed to bootstrap events into our personalization hub, and do so in real-time.
Tracking user event data is one of the many important parts in building a personalization system. The more we know about a user, the better we can personalize content to the user. To that end, it was important to think about how we modeled user events as we tracked user events. The tracking pixel data format we historically used is very different compared to our JSON data models, and we were going to have to apply a complex transformation on the tracking pixel data to the format of our master data set. Data governance is central to our event tracking system and we would have to apply strict data governance to our bootstrapping of events. Apache Flume would allow us to both transform and validate the tracking data and we would be able to do this in real-time, which was the solution we needed.
Transforming the Data in Real-time
We decided to use Flume Interceptors to perform the transformation of the tracking pixel data to our JSON data model. Flume Interceptors allow Flume to modify or drop events in real-time. We were able to create an interceptor that applied transformations layer-by-layer to the tacking pixel data and eventually validate the transformation to ensure it conforms to our data model, ensuring strict data governance. If the log entry failed to transform or validate, we discarded it by placing it in a location in HDFS for invalid events.
Building a Fail Safe Topology
When designing the Flume topology, we had to be considerate of several constraints. We needed a topology that was easily deployable, scalable, and maintainable. The topology needed to be fail safe at every layer because of the critical nature of event tracking, and lastly, we needed the topology to handle recovery smoothly in the case of a failure. Our Flume topology ended up looking like this:
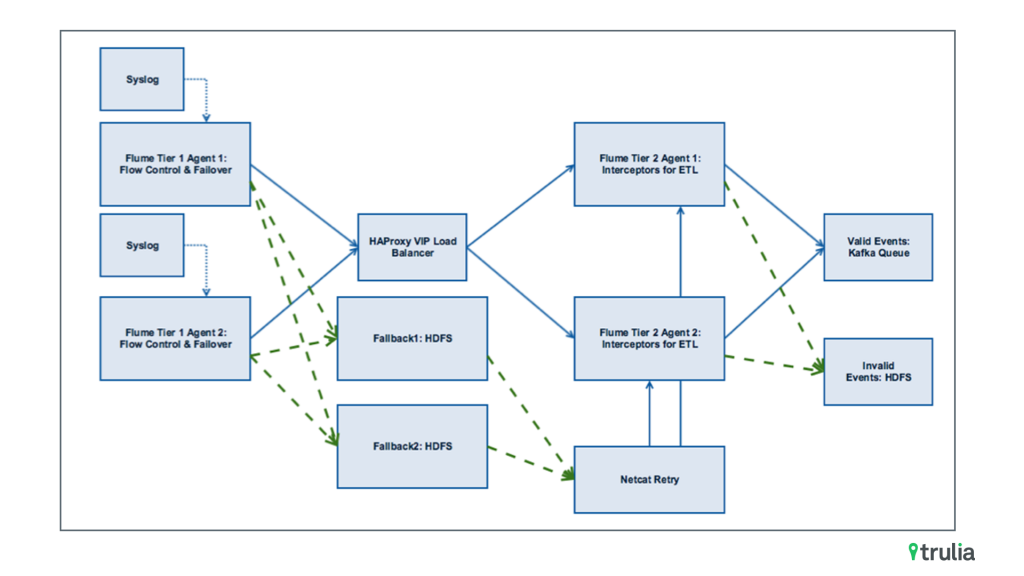
The above topology is easily deployable and maintainable. Because we separated the Flume agents into two tiers, we are able to install a Flume agent on tier one, which has a Syslog source and Avro sink. This agent sits on very important production hardware that we do not want to accidentally disturb. Our tier two houses a second Flume agent that has an Avro source with a Kafka sink. Most importantly, this is where our interceptor sits as well so that if we need to modify our interceptor logic, we can release new versions of our interceptor to tier two so that we never touch our tier one agent. This has been especially useful as our tier one agent was deployed Summer 2015 and we have not needed to manage it. Additionally, the overhead of doing the ETL is on the second tier, so the more critical production machines do not use resources on ETL. Finally, this topology is easily scalable. Because we use an HAProxy for load balancing, we can add additional machines to each tier and just modify the configuration of the HAProxy to receive and send data from additional machines.
The above topology is also failsafe at every layer and amongst all of our development and production environments. If the upstream components go down (i.e. Kafka), then the downstream components have a failover mechanism. We do this by taking advantage of Flume’s Failover Sink Processor. This allows us to specify where to direct events in the case of failover. For example, if Kafka were to go down, then Flume tier two would go down causing Flume tier one to send events to HDFS. Our Flume tier two agent has an additional Netcat source which we can use to replay events from HDFS into Flume. We designed the replay services to be done offline rather than online to prevent additional strain on the system.
Designing and building this system was a rewarding experience. This system has allowed Trulia to bootstrap over 10 billion events in real-time, while maintaining our strict data governance and has remained exceptionally stable since being deployed more than a year ago.

