Trulia’s Data Science team has several projects seeking to drive the foundation of Trulia in a data-centric direction, such as image recognition, text generation and understanding, recommendation and relevance systems and many more. These projects rely on machine learning, which requires massive amounts of data.
Given the scope of these projects, Trulia needed a way for its data scientists to seamlessly collect data provided by human workers for use in machine learning applications. As a summer intern on the team, I was tasked with this project, which served as an opportunity to learn new technologies and practice tools and languages I was not yet familiar with. I specifically worked on developing three main components of this system:
Interfacing with crowd sourcing backends
For starters, we needed an online crowdsourcing platform that would allow us to connect with a large pool of human workers who were willing to work on our data collection tasks. We decided to use Amazon Mechanical Turk (AMT) as our initial backend since it is one of the most widely used crowd platforms. Using boto3, a python SDK allowing communication with AMT, we are able to post tasks online for workers to view and complete.
Our design focuses on abstracting out the complexities of the crowd backends from users, which allows us to migrate and utilize alternative crowd platforms in the future, including hosting tasks on in-house servers for internal workers.
Building the template engine for worker tasks
Once we had the crowd platform sourced, our next focus was on designing tasks. Elegant design was essential. Every worker wants to complete as many tasks as quickly as possible, in order to maximize their revenue, so ensuring a high-quality user interface with readable instructions is a must. On the other hand, a data scientist requires data meeting a strict set of parameters, meaning accuracy is of utmost importance. Without explicit instructions in the task, we found worker’s answers to be wildly inconsistent and unusable. “Draw a bounding box around windows in the image” can mean something very different to each worker.
To build the right template for our tasks, I studied HTML, CSS and JavaScript, with extensions leading into JavaScript libraries. Intermediate to advanced skill was necessary to drive the complex functions we needed to acquire the desired data.
For example, Jquery and Jcrop, both libraries of JavaScript, were used to develop a task for gathering bounding box annotations for objects in real estate photos. The template allowed workers to draw boxes around objects of interest (e.g. windows) in the displayed images, in turn getting us the exact data we needed.
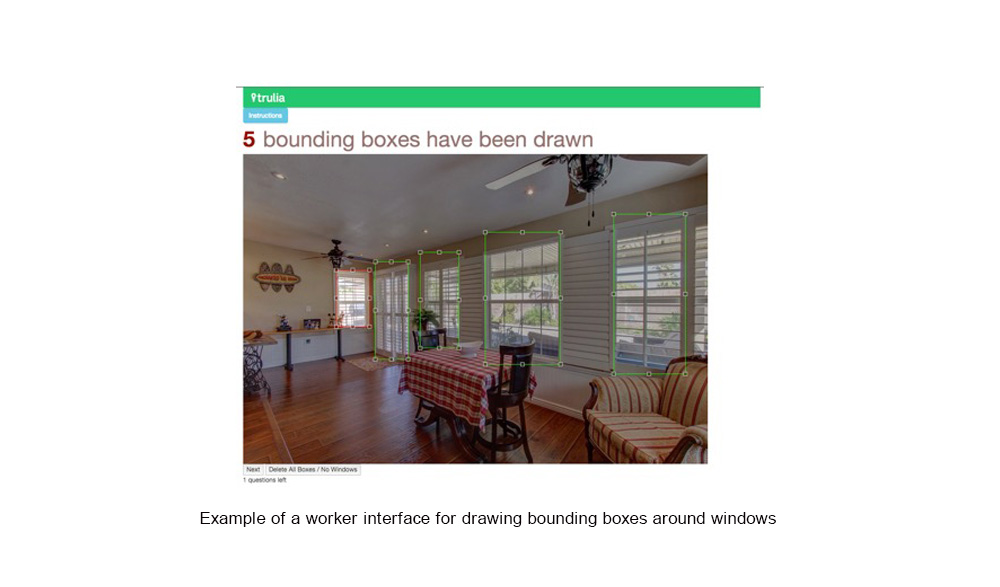
Another focus of our implementation was to develop reusable templates so that new crowdsourcing tasks could be quickly bootstrapped from existing templates, saving data scientists valuable time. We used Jinja2, a templating language that integrates with Python, to create generic task templates for our various data gathering needs. This enabled us to generate several different types of worker tasks, from categorizing real estate photos for Trulia’s hero images to collecting similarities for natural language processing projects.
Crowdsourcing as a service
The core of the program is written in Python and uses Django, a web framework that allows the system to be accessible as a RESTful API service. Redis was used as the backend database to store information on the tasks, worker responses and their statistics. The REST API allows users to create new projects, post tasks, assign qualifications to workers, monitor task status, and retrieve results and worker statistics. This enables existing applications to seamlessly integrate with the API to create an automated workflow for data collection.
Results and future work
This project is still under development, with the roadmap including continued standardization of task templates, automatic evaluation of workers, UI improvements for a better integrated experience, and data analysis and cleaning. It is being actively used for collecting annotations for Trulia real estate photos to improve its in-house image recognition technology. The bounding box annotation task is being used to collect data for training deep learning models for detecting objects in real estate photos.

My internship is now over, and I learned an incredible amount and applied it to an actual large-scope project. I grew more intimate with web development and added the beautiful language Python to my repertoire. Not to mention, I was able to participate in some pretty cool projects outside of this one during Trulia’s quarterly Innovation Weeks – I met new people, learned new technologies and had a blast along the way. Overall, this was my first experience in a non-academic coding environment, and the freedom in approaching and solving problems was amazing. I can’t wait to see how this project continues to unfold at Trulia.

