Trulia’s Data Science team helps surface relevant and unique content to our consumers through Recommendations, Computer Vision and NLP. But, with millions of consumers visiting Trulia every month and millions of properties available for sale or rent at any given moment, the scalability challenges are not for the faint of heart. Being able to iterate on models at scale becomes critical in making sure we are able to surface the most relevant content to our consumers. To this end, we recently embarked on a journey to move our ad-hoc development from our in-house Hadoop cluster to Amazon Web Services (AWS) EMR on Spark. Here’s a look at our experience going through this process.
Why AWS?
Until recently, we had relied on our in-house cluster equipped with Apache stack of Big Data technologies (HDFS, MapReduce, Hive, etc.) managed by a small team of DevOps. The cluster was used to run regular workflows as well as ad-hoc experimentation. However, as our audience size grew, the complexity of our workflows exploded and our in-house cluster’s capacity started to feel insufficient. We increasingly found ourselves trying to coordinate with other Data Engineers when our workflows could be run. We also had to carefully manage our workflows so as to fit the entire workload on the cluster and leave sufficient room for ad-hoc experimentation. Language versioning issues (Java 1.6 vs 1.8, Python 2.7 vs 3.0, etc.) and each team’s need for maintaining a custom development environment (different scipy/scikit-learn versions for different teams on the cluster nodes) complicated things further. We began spending a non-trivial amount of time dealing with our cluster. We had already started to run some of our newer production workflows on AWS, so we decided to give AWS a try for our ad-hoc development environment as well.
AWS EMR ticked all the boxes for us – cluster size is only constrained by cost, we could spin up a new cluster with the latest and greatest Big Data stack at literally the click of a button. The migration to AWS also coincided with our migration away from Hadoop MapReduce to Apache Spark. Spark’s superior performance is well documented. The ability to use expressive languages such as Python or Scala held particular appeal for us since we use these languages for modeling purposes.
Local Spark Driver
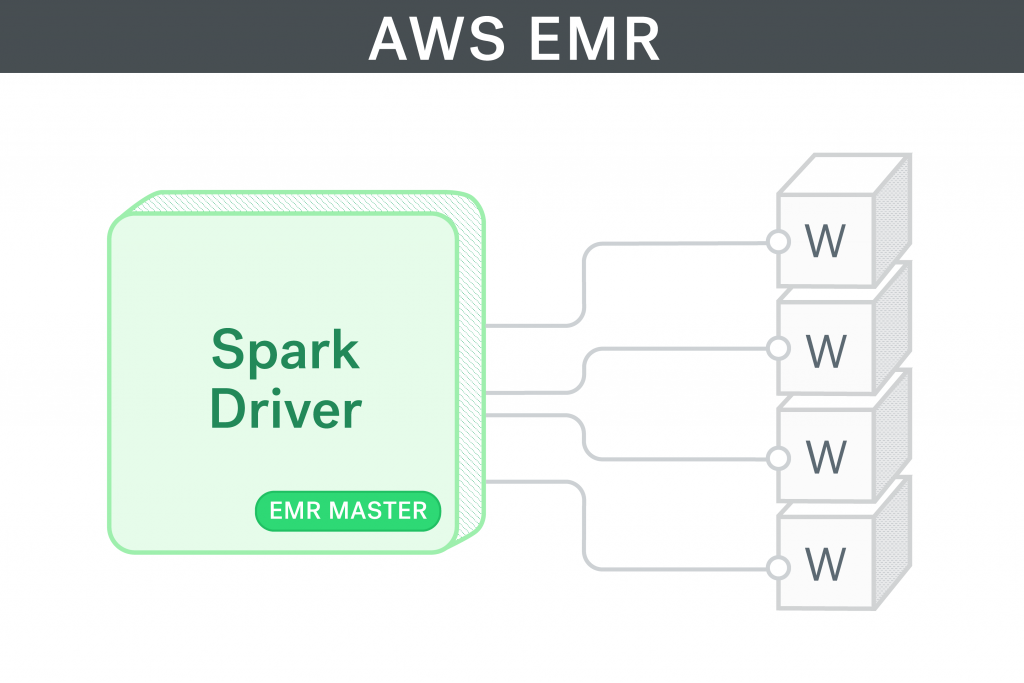
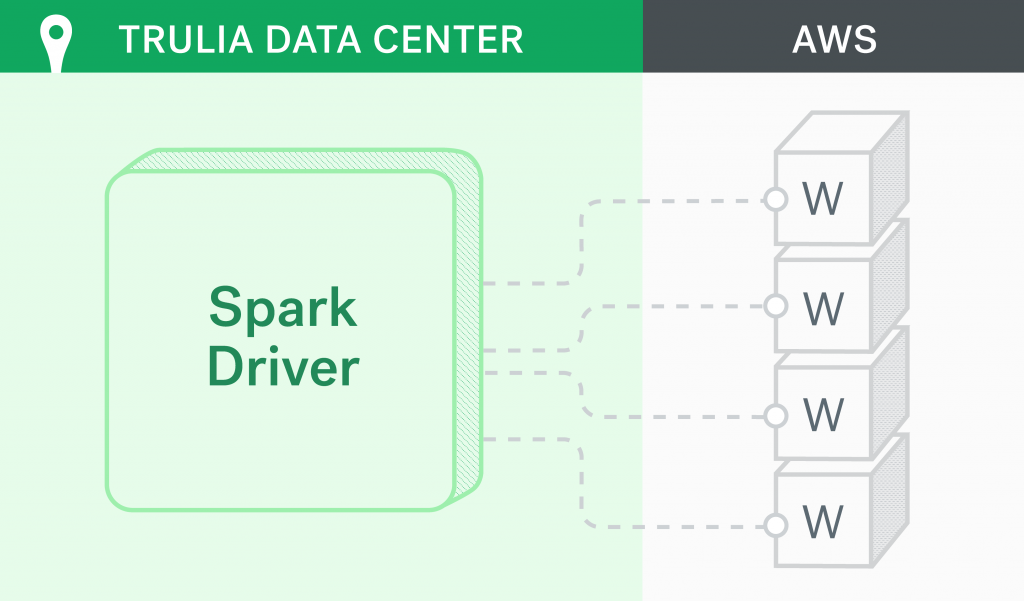
When you bring up an AWS EMR cluster with Spark, by default the master node is configured to be the driver. For ad-hoc development, we wanted quick and easy access to our source code (git, editors, etc.). We might also connect to some in-house MySQL servers and run some queries before submitting the spark job. Setting up our own machines as spark drivers that connected to the core nodes on EMR would have been ideal. Unfortunately, this was impossible to do and we forfeited after trying many configuration changes. The driver would start up and then keep waiting unsuccessfully, trying to connect to the slaves.
Most of our Spark development is on pyspark using Jupyter Notebook as our IDE. Since we had to run Jupyter from the master node, we couldn’t risk losing our work if the cluster were to go down. So, we created an EBS volume and attached it to the master node and placed all of our work on this volume.
Bootstrapping
We also created a script that we run on the master node every time we launch a new cluster. This script mounts the EBS volume, creates user accounts for every member of our team, and sets up home directories and user permissions. For some of the models we develop, training is done on a single node and we use the master node for this. So, we also install any Python packages that we need for training our models through this script.
EMR Auto-scaling and Spark Dynamic Allocation Don’t Mix
Late last year, Amazon announced support for auto-scaling with EMR. This seemed like the perfect solution for our ad-hoc development needs. Spark’s dynamic allocation requests YARN containers dynamically when a job is submitted based on the amount of parallelism in your data. When a large job is submitted or when more developers connect to the cluster, as more YARN containers are allocated, auto-scaling would kick in to add more nodes to the cluster.
Perfect right? Well, not quite…we started seeing errors like this when we reused an RDD after the cluster was shrunk down: “org.apache.spark.shuffle.FetchFailedException: Failed to connect to…
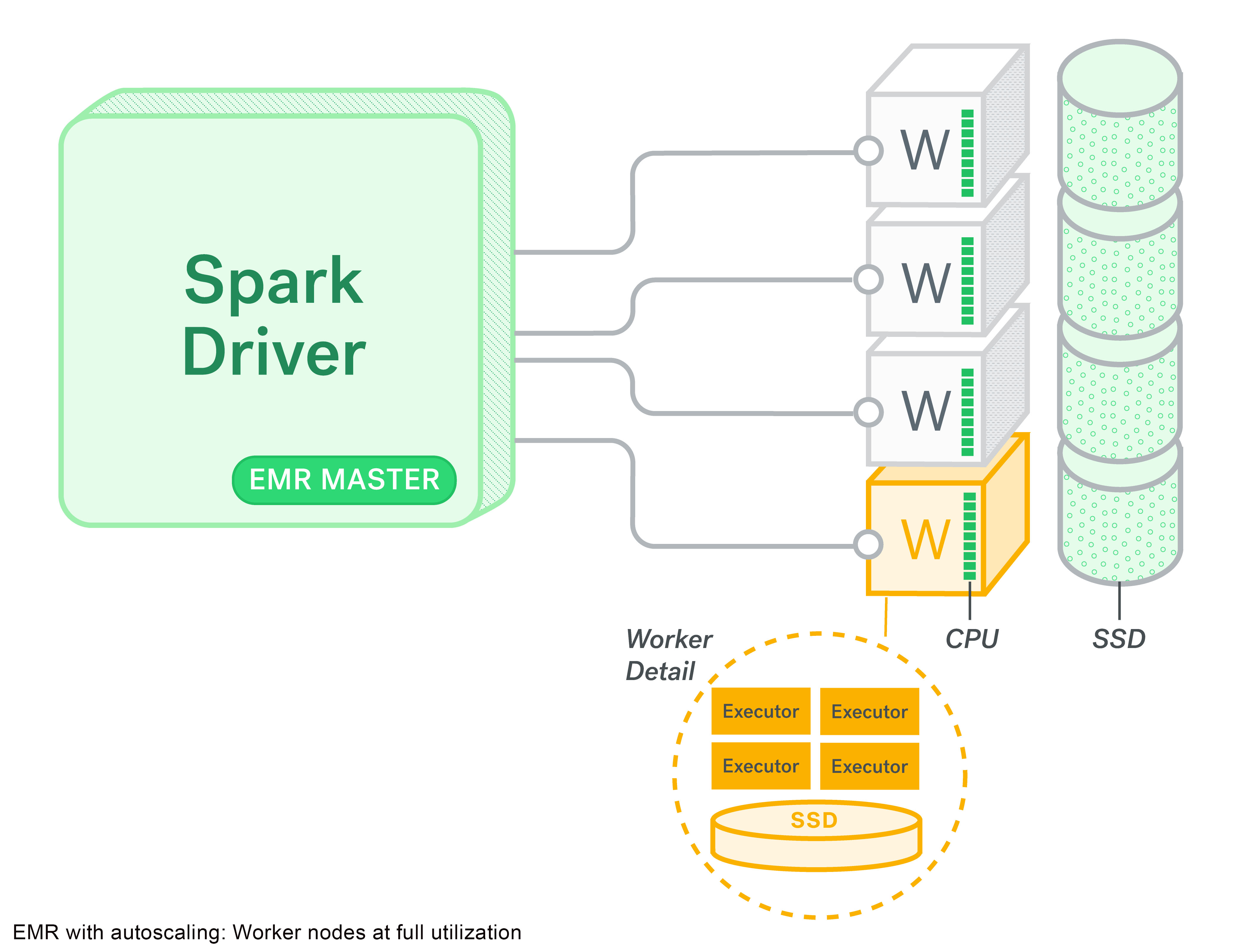
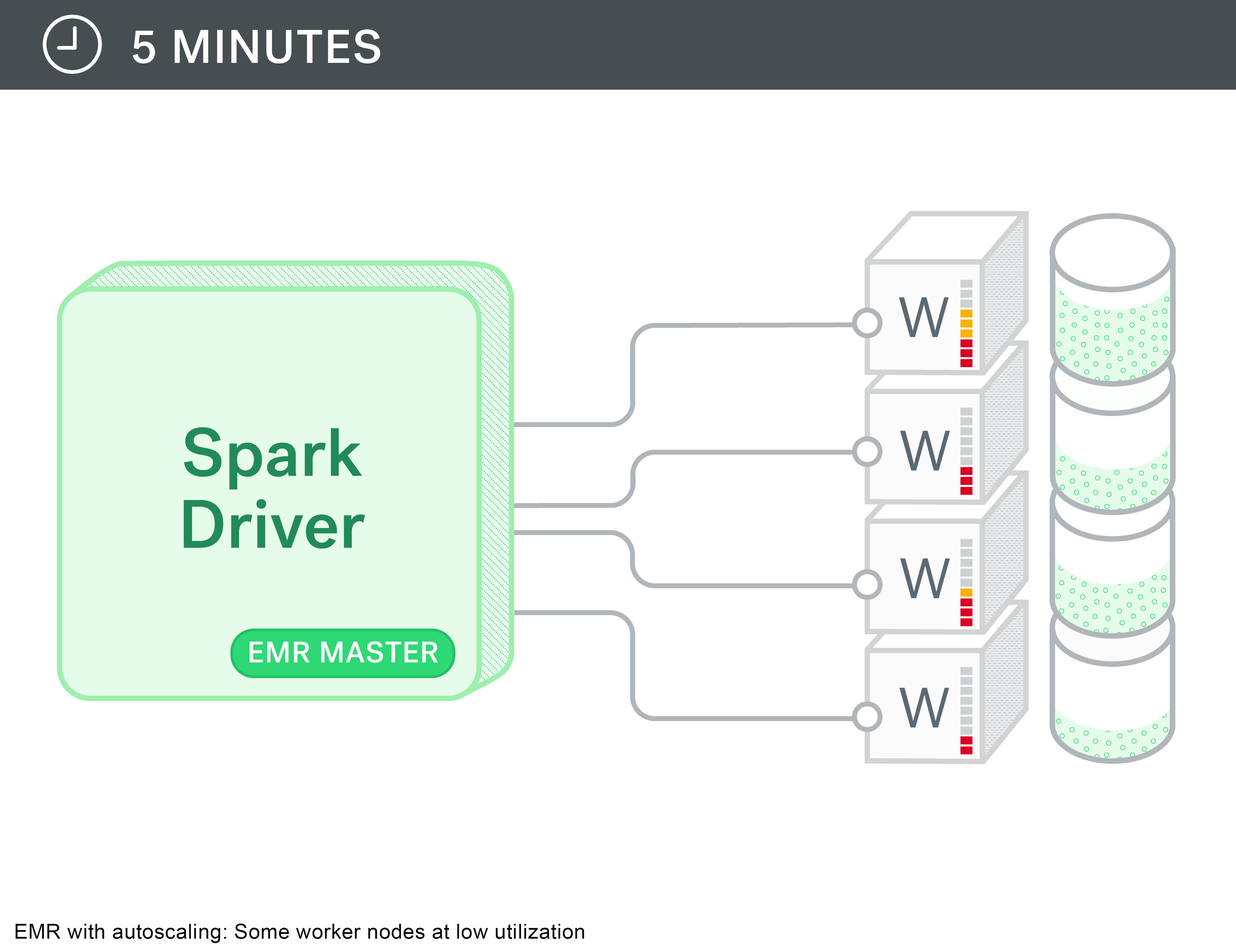
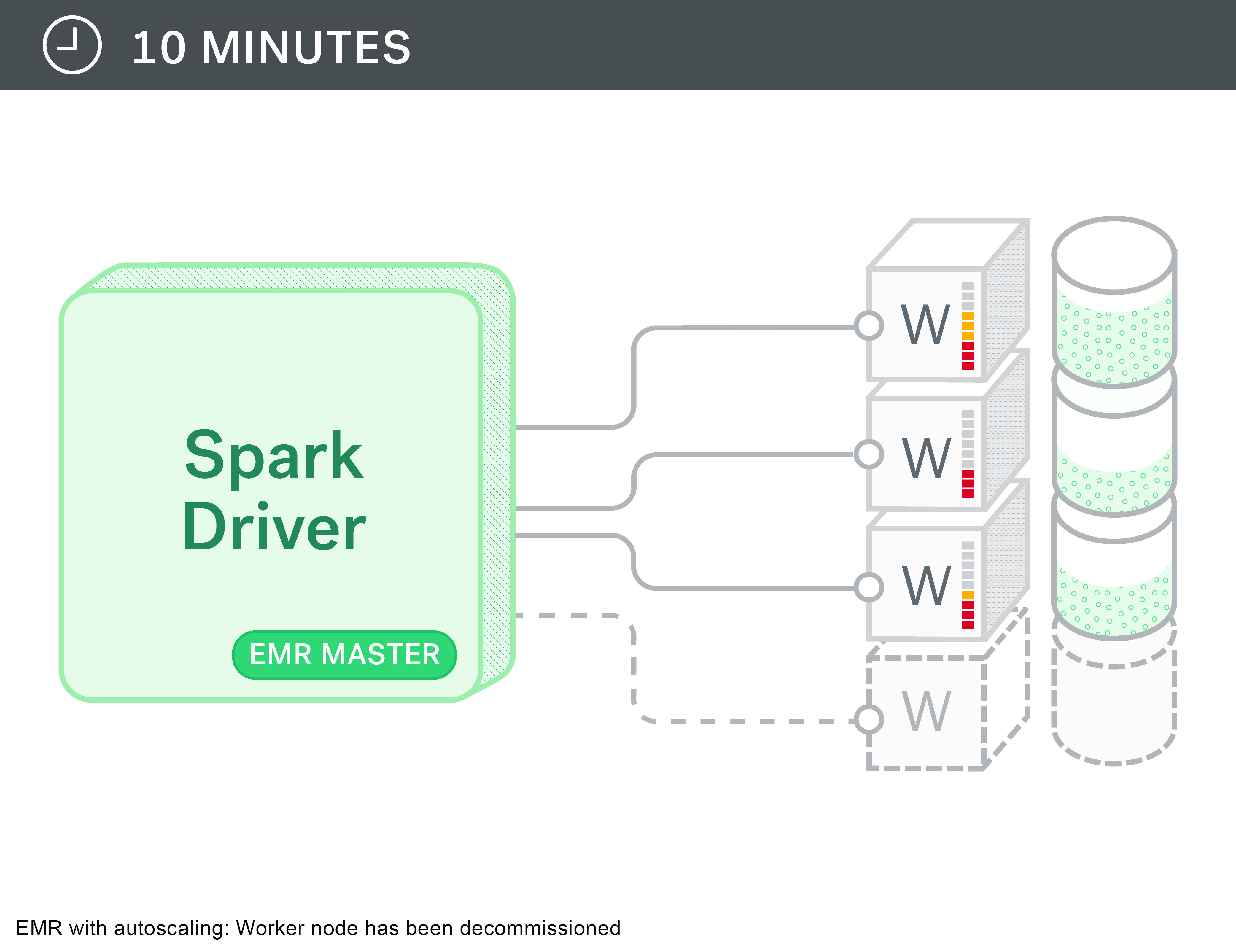
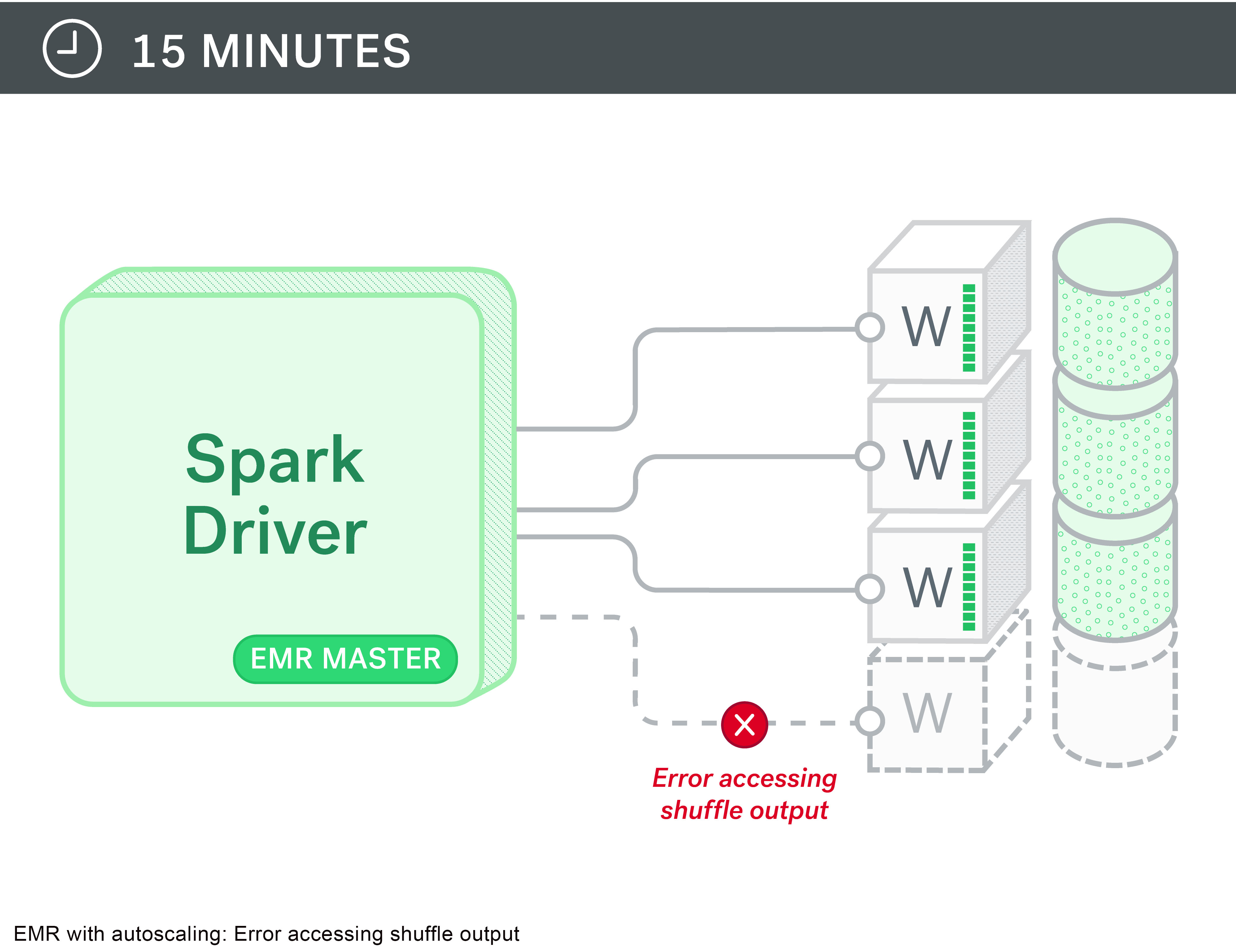
Turns out, Spark task stores its shuffle output in the local disks of the node and they are available through the external shuffle service that runs on the nodemanager service on every node. The idea being that when an executor is completed, you can still get its output files from the nodemanager external shuffle service. But, with auto-scaling, these nodes get decommissioned and that output is no longer available.
We then switched to a model of manually scaling up and scaling down as needed. Not as convenient, but it still gets the job done. We also setup some cron jobs on the master node to scale the cluster down late in the evening to avoid cost run-ups.
With these adjustments we are now able to successfully use EMR for our day-to-day development.
Wish List
EMR offers Zeppelin as a notebook IDE that can be installed. It would be nice to offer Jupyter as option – a popular notebook IDE among Python developers.
Occasionally we have to install some packages on the slave nodes. While it’s fairly easy to write a script to do this, doing this on any new node that might come up is bit more work. A Puppet like package manager for the cluster would be very convenient.
Overall, we are much more nimble and efficient as a team with our switch to AWS for our ad-hoc development. The ability to be on the bleeding edge of Big Data/Data Science stack far outweighs the challenges we faced, which means we are able to deliver content that our consumers want.

